虎符签到题handle,连官方wp都叫你直接随便选一个看起来过得去的就行,确实是handle里对于开头的成语基本没啥讲究,但是反正做都做了不如做完做好,于是就又花了些时间跟着3b1b的wordle视频做了个这,主要是信息论 的应用和对C++的顺便实操
HandleCrack[信息论] 为了文章长度尽量短点(懒),以下是我略过但读者应该知道的内容:
handle 和wordle的规则E = ∑ -p_i * log(p_i)
(直接去看一遍3b1b视频 多好,以及另一个3b1b的补充说明 )
Q&A >> 问:原题不是py吗怎么要扯cpp?
答:不会优化py所以我的cpp跑起来应该比py快(?),而且cpp的位操作和手动内存管理我看着要放心一点(执念(不要学我(呜
>> 问:不是随便选一个当开头词就可以了吗,为什么还要费这么大力气整这些?
答:一,看了wordle的视频自己也想实操一下;二,反正比赛都结束了不如做完善点;三,不求出来我会睡不着觉的。总之就是虽然确实根据最后的结果看来,只要选一个比较正常的成语,或者多试几个开头词,就能达到很好的效果了,但是我就是想做一下,因为挺有趣的
题面 Handle在4轮内找到答案,重复512次,每次的选词由random.choice()产生
然后就是他这个交互有点难受,由于你输入词语后它返回的拼音对错信息是以颜色标注的,虽然听群里说字节流下颜色可以比较方便的获取,但是反正后面我复现的时候是没有管这个的
下载链接(github源)
Handle杂谈 wordle是固定5个字母,每个字母框有三种情况,所以理论上总共的可能性是3^5种
handle是固定4个拼音,每个字的拼音分为声母,韵母,声调,所以可以看作是12个字母的wordle,也是每个拼音框有三种情况,理论可能性有3^12种
特殊韵母 但是中文中包含特殊韵母,比如 en,er,ei 等,一个韵母就是一个注音的字。那比如这一轮猜了读音为 en 的一个字,则不管才没猜对,都损失了一个位置上声母的信息,特别是 en,ei 这些可以和声母搭配,又可以自己来的特殊韵母,对于 er 而言,由于 er 不能和声母组合,会更特殊一点(顺便一提,py的拼音库得出的拼音不知为何对“了”这个字也没有音调,所以有些时候不止会在声母上为空,声调也有可能为空)
但是我已经不想思考了,所以我就把 er 和 en,ei 之类的同等处理的,也许把 er 再单独分出来又会稍微不一样一捏捏,但是我真的已经停止思考了
词库 其实我当时以为他题目没给代码,查了一下常用成语貌似也就几千个,我就去百度汉语扒了一个百度的成语词库,那也才4000个词啊,好家伙结果他给的那个列表有将近两万六千个词(?),看了一下是从这里面 搬的,里面甚至有“可口可乐” 之类的特别奇怪的东西,哈哈 (^ ^)
exp 这个exp里不包含对上面提到的特殊韵母的特殊处理,同时直接用的函数return的信息来反馈的,而不是题目环境下的颜色信息
吐槽 exp的思路很简单,的确只需要比较随便的选择开局的词语就可以了,甚至第一个词“一丁不识”在最后算出来的信息熵排名里面都很靠前,只要不是“可口可乐”这种奇怪的词,就可以在运气的加持下直接出flag,说实话这个flag是必须要运气的,因为就算是我最后算出来的信息熵最高的词他也不能保证4轮出结果,我得到的平均轮次大概是2.62轮(和题目条件一样随机抽取测试512次),而被我目击到的最大轮次是6轮,虽然我写的这个脚本优化比较烂,但是还是不影响我说:这个题他应该看你到最后的平均轮次是否合格,而不是看最大轮次 = =
在的官方wp 里对他自己的exp表示:
这个脚本也不是必成功,但是体感成功率非常高,平均猜词次数 2.72,也许换个起始词可以把最大次数压到 3
哥你得有数据啊不要凭感觉啊,出题人可能是觉得他随便选了个词就可以把平均猜词数压倒2.72,所以优化一下应该能轻松压得很低,但是问题就是其实这些词语的信息熵的分布总体来看都算是比较高的了,总共不到2.6w个词,2.1w个词的信息熵在10以上,最高的信息熵也就12.8755,意思是你随便选中那2.1w个信息熵在10以上的词的时候,理论上剩下的词数的期望就只有25.3个,但3b1b讲wordle的视频里有句话说得好,就,“期望是期望,实际是实际”(大概是这个意思),所以还是那句话,最好就存一下选手的轮次信息,最后算一下平均轮次够不够小
在我抽的512抽里面大概是这么个分布
1 2 3 猜中轮次 -| 一发入魂 | 2 | 3 | 4 | 5 | 6 | ----------------------------------------------------------------------- 发生次数 -| 1 | 230 | 247 | 32 | 1 | 1 |
Source 挺无脑的,py水平有限,有些地方不太优雅
exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 initials, finals, tones = [], [], [] for word in idioms: pinyin = get_pinyin(word) initials.append(pinyin[0 ]) finals.append(pinyin[1 ]) tones.append(pinyin[2 ]) def GetWord (words ): wordLen = len (words) if wordLen > 25000 : return "研经铸史" E = [] for guessIndex in range (wordLen): partern, count, prob = [], [], [] for ansIndex in range (wordLen): result = [] result.append(check_part(initials[guessIndex],initials[ansIndex])) result.append(check_part(finals[guessIndex],finals[ansIndex])) result.append(check_part(tones[guessIndex],tones[ansIndex])) findFlag = False for i in range (len (partern)): if partern[i] == result: count[i] += 1 findFlag = True break if not findFlag: partern.append(result) count.append(1 ) for i in range (len (partern)): p = count[i] / wordLen prob.append(-p * log2(p)) E.append(sum (prob)) print("\r>> E: " + str (guessIndex), end='' ) print("\n>> max E: " + str (max (E))) return words[argmax(E)] def DeleteWord (words, result, guess ): certain = [] uncertain = [] wrong = [] pinyin = get_pinyin(guess) for i in range (3 ): for j in range (4 ): if result[i][j] == status.OK: certain.append([pinyin[i][j],(i,j)]) elif result[i][j] == status.MISS: uncertain.append([pinyin[i][j],(i,j)]) else : wrong.append([pinyin[i][j],(i,j)]) newWords = [] for wordIndex in range (len (words)): pinyin = get_pinyin(words[wordIndex]) flag = True and words[wordIndex] != guess for i in certain: if pinyin[i[1 ][0 ]][i[1 ][1 ]] != i[0 ]: flag = False break if not flag: continue for i in uncertain: if i[0 ] not in pinyin[i[1 ][0 ]] or i[0 ] == pinyin[i[1 ][0 ]][i[1 ][1 ]]: flag = False break if not flag: continue for i in wrong: if i[0 ] in pinyin[i[1 ][0 ]]: wrongCnt = pinyin[i[1 ][0 ]].count(i[0 ]) certainCnt, uncertainCnt = 0 , 0 for j in certain: certainCnt += j.count(i[0 ]) for j in uncertain: uncertainCnt += j.count(i[0 ]) if wrongCnt <= certainCnt + uncertainCnt: continue flag = False break if not flag: continue newWords.append(words[wordIndex]) return newWords
最优开头 我其实之前想过能不能直接构造一个最优开头,但是没什么思路,就决定从他给出的2.6w个词里面找一个最优开头
由于文章一开头说的优化问题,所以我就py2cpp()了
准备工作 首先我把所有词的拼音都通过py的拼音库导出到了硬盘,无韵母无声调的地方用“#”进行了占位,然后为了之后不再重复统计一个词另一个词比较得出的pattern,我把所有partern导出,这样之后查表就完事了
这一块值得注意的应该也就是pattern的存储格式 了
因为每一个拼音位有4种情况:确定存在且位置正确,确定存在但位置错误,确定不存在,不确定是否存在(特殊韵母);而总共4个汉字,每个汉字3个拼音位,由于状态共4种,两位就能表示完(00,01,10,11),总共需要4 * 3 * 2 = 24(bit),刚好3字节,所以用3个char就可以塞下1个pattern,这部分详见下方折叠代码中的CalPattern()
crackGen.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 #include <iostream> #include <fstream> #include <list> #define MAXSIZE 26352 using namespace std ;struct ZHword { string pinyin[12 ]; }; void InitZHWords (list <ZHword> &words) ifstream f_ini("initials.txt"), f_fin("finals.txt"), f_ton("tones.txt"); string str_ini, str_fin, str_ton; int cnt = 0 ; ZHword wordTemp; while (f_ini >> str_ini && f_fin >> str_fin && f_ton >> str_ton) { wordTemp.pinyin[cnt % 4 * 3 ] = str_ini; wordTemp.pinyin[cnt % 4 * 3 + 1 ] = str_fin; wordTemp.pinyin[cnt % 4 * 3 + 2 ] = str_ton; if (!(++cnt % 4 )) words.push_back(wordTemp); } f_ini.close(); f_fin.close(); f_ton.close(); } bool CalPattern (ZHword guess, ZHword answer, char *pattern) list <string > miss; list <string >::iterator iterMiss; for (int i = 0 ; i < 12 ; i++) { if (guess.pinyin[i] == "#" ) { pattern[i % 3 ] |= 3 << (3 - i / 3 ) * 2 ; miss.push_back(answer.pinyin[i]); } else if (guess.pinyin[i] != answer.pinyin[i]) miss.push_back(answer.pinyin[i]); else pattern[i % 3 ] |= 2 << (3 - i / 3 ) * 2 ; } if (miss.empty()) return true ; for (int i = 0 ; i < 12 ; i++) { int marked = int (pattern[i % 3 ] >> ((3 - i / 3 ) * 2 ) & char (0x3 )); if (marked) continue ; for (iterMiss = miss.begin(); iterMiss != miss.end(); iterMiss++) if (guess.pinyin[i] == *iterMiss) { pattern[i % 3 ] |= 1 << (3 - i / 3 ) * 2 ; miss.erase(iterMiss); break ; } } return false ; } int main () char *patternsHead[MAXSIZE]; for (int i = 0 ; i < MAXSIZE; i++) { char *patterns = new char [3 * MAXSIZE](); patternsHead[i] = patterns; } list <ZHword> zh_words; list <ZHword>::iterator guess, answer; InitZHWords(zh_words); int cntGuess = 0 ; for (guess = zh_words.begin(); guess != zh_words.end() && cntGuess < MAXSIZE; guess++, cout << cntGuess++ << endl ) { int cntAns = 0 ; for (answer = zh_words.begin(); answer != zh_words.end(); answer++, cntAns++) CalPattern(*guess, *answer, &patternsHead[cntGuess][cntAns * 3 ]); } ofstream f ("patterns.dat" , ios::out | ios::binary) ; for (int guessIndex = 0 ; guessIndex < MAXSIZE; guessIndex++, cout << "SAVE: " << guessIndex << endl ) for (int ansIndex = 0 ; ansIndex < MAXSIZE; ansIndex++) f.write(&patternsHead[guessIndex][ansIndex * 3 ], 3 ); f.close(); zh_words.clear(); return 0 ; }
main 做好了patterns的准备工作,就可以开始求E了
对于GetEntropy()总共就三步:
存储结构上要提一下,如果直接创建超大数组多半会segFault,所以我用的拉链法
1 char patterns[MAXSIZE][MAXSIZE * 3 ];
1 2 3 4 5 6 char *patternsHead[MAXSIZE];for (int i = 0 ; i < MAXSIZE; i++){ char *patterns = new char [3 * MAXSIZE]; patternsHead[i] = patterns; }
以及递归深度方面,由于深度只要不为0就算的真的太慢了,所以我也和3b1b一样,计算深度为1的数据时只拿在深度为0时排名靠前的数据去计算,以减少对获取最优开头词的无效计算
crack.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 #include <iostream> #include <fstream> #include <list> #include <math.h> #include <cstring> #define MAXSIZE 26352 #define TOP 100 using namespace std ;char *patternsHead[MAXSIZE];struct PatternRecord { char pattern[3 ] = {0 }; int count = 1 ; }; struct EntropyRecord { float E = 0 ; int index; }; bool cmp (EntropyRecord A, EntropyRecord B) return A.E > B.E; } void InitWords (string *words) ifstream f_word ("idioms.txt" ) ; string str_word; int cnt = 0 ; while (f_word >> str_word) words[cnt++] = str_word; f_word.close(); } bool SamePattern (char *guessPattern, char *answerPattern) if (guessPattern[0 ] == answerPattern[0 ] && guessPattern[1 ] == answerPattern[1 ] && guessPattern[2 ] == answerPattern[2 ]) return true ; return false ; } void GetRecords (char *patterns, list <PatternRecord> &records, list <int > enabled) list <PatternRecord>::iterator iterGuessRec; list <int >::iterator iterEn = enabled.begin(); for (int i = 0 ; i < MAXSIZE; i++) { if (!enabled.empty() && i != *iterEn) continue ; PatternRecord ansRecord; memcpy (ansRecord.pattern, &patterns[i * 3 ], 3 ); bool match = false ; for (iterGuessRec = records.begin(); iterGuessRec != records.end(); iterGuessRec++) if (SamePattern((*iterGuessRec).pattern, ansRecord.pattern)) { (*iterGuessRec).count++; match = true ; break ; } if (!match) records.push_back(ansRecord); iterEn++; } } list <int > UpdateEnabled (char *patterns, char *pattern, list <int > lastEnabled) list <int > enabled; list <int >::iterator lastPtr; for (lastPtr = lastEnabled.begin(); lastPtr != lastEnabled.end(); lastPtr++) if (SamePattern(&patterns[(*lastPtr) * 3 ], pattern)) enabled.push_back(*lastPtr); return enabled; } EntropyRecord GetEntropy (int depth, int guessIndex, list <int > &enabled) list <PatternRecord> patternRecords; list <float > patternERecs; GetRecords(patternsHead[guessIndex], patternRecords, enabled); if (depth) for (list <PatternRecord>::iterator iterPRec = patternRecords.begin(); iterPRec != patternRecords.end(); iterPRec++) { list <int > newEnabled; if (enabled.empty()) { for (int i = 0 ; i < MAXSIZE; i++) if (SamePattern(&patternsHead[guessIndex][i * 3 ], (*iterPRec).pattern)) newEnabled.push_back(i); } else for (list <int >::iterator iterEn = enabled.begin(); iterEn != enabled.end(); iterEn++) if (SamePattern(&patternsHead[guessIndex][(*iterEn) * 3 ], (*iterPRec).pattern)) newEnabled.push_back(*iterEn); list <float > localERecords; if (newEnabled.size() < 2 ) localERecords.push_back(1 ); else for (list <int >::iterator newGuessIndex = newEnabled.begin(); newGuessIndex != newEnabled.end(); newGuessIndex++) localERecords.push_back(GetEntropy(depth - 1 , *newGuessIndex, newEnabled).E); float localMax = 0 ; for (list <float >::iterator iterERec = localERecords.begin(); iterERec != localERecords.end(); iterERec++) if (localMax < *iterERec) localMax = *iterERec; patternERecs.push_back(localMax); } EntropyRecord entropyRecord; entropyRecord.index = guessIndex; list <PatternRecord>::iterator iterP = patternRecords.begin(); list <float >::iterator iterE = patternERecs.begin(); for (; iterP != patternRecords.end(); iterE++, iterP++) { float prob = float ((*iterP).count) / float (enabled.empty() ? MAXSIZE : enabled.size()); entropyRecord.E += -prob * log2(prob); } if (depth) { iterP = patternRecords.begin(); iterE = patternERecs.begin(); for (; iterE != patternERecs.end(); iterE++, iterP++) { float prob = float ((*iterP).count) / float (enabled.empty() ? MAXSIZE : enabled.size()); entropyRecord.E += prob * (*iterE); } } return entropyRecord; } int main () string words[MAXSIZE]; InitWords(words); ifstream f_in ("patterns.dat" , ios::in | ios::binary) ; for (int i = 0 ; i < MAXSIZE; i++) { char *patterns = new char [3 * MAXSIZE]; patternsHead[i] = patterns; f_in.read(patterns, MAXSIZE * 3 ); } f_in.close(); list <int > enabled; list <EntropyRecord> entropyRecords, topERecs; for (int guessIndex = 0 ; guessIndex < MAXSIZE; guessIndex++) { EntropyRecord myEntRec = GetEntropy(0 , guessIndex, enabled); cout << ">> D0-No." << guessIndex << " " << words[guessIndex] << " complete with E of " << myEntRec.E << endl ; entropyRecords.push_back(myEntRec); } entropyRecords.sort(cmp); list <EntropyRecord>::iterator iterERec = entropyRecords.begin(); ofstream f_word("d0rankedWord.txt"), f_E("d0rankedE.txt"); for (int cnt = 0 ; iterERec != entropyRecords.end(); iterERec++, cnt++) { f_word << words[(*iterERec).index] << endl ; f_E << (*iterERec).E << endl ; } f_word.close(); f_E.close(); iterERec = entropyRecords.begin(); for (int cnt = 0 ; cnt < TOP; iterERec++, cnt++) { EntropyRecord myEntRec = GetEntropy(1 , (*iterERec).index, enabled); cout << ">> D1-No." << cnt << " " << words[(*iterERec).index] << " complete with E of " << myEntRec.E << endl ; topERecs.push_back(myEntRec); } topERecs.sort(cmp); f_word.open("d1rankedWord.txt" ); f_E.open("d1rankedE.txt" ); for (iterERec = topERecs.begin(); iterERec != topERecs.end(); iterERec++) { f_word << words[(*iterERec).index] << endl ; f_E << (*iterERec).E << endl ; } f_word.close(); f_E.close(); return 0 ; }
其他 其实我是准备吧handle完整搬到c++上来的,结果代码弄完了发现我不知道怎么让c++支持中文输入(?
但是不准备继续日了,放个之前的代码
crackGen.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 int GetRand (int seed=0 ) srand(seed ? seed : (int )time(NULL )); return rand() % MAXSIZE; } void ShowMatch (char *partern, ZHword guess) for (int i = 0 ; i < 4 ; i++, cout << " " ) for (int j = 0 ; j < 3 ; j++) { int index = j + 3 * i; if ((int )partern[index] == 2 ) cout << "[" << guess.pinyin[index] << "]" ; else if ((int )partern[index] == 1 ) cout << "<" << guess.pinyin[index] << ">" ; else cout << guess.pinyin[index]; } cout << endl ; } bool StartRound (int roundLimit, list <ZHword> words) list <ZHword>::iterator answer = words.begin(); advance(answer, GetRand() - 1 ); for (int round = 0 ; round < roundLimit; round++) { list <ZHword>::iterator guess; string guessIn; char results[12 ] = {0 }; cout << ">> Round: " << round << endl ; cin >> guessIn; for (guess = words.begin(); guess != words.end(); guess++) if ((*guess).word == guessIn) break ; if ((*guess).word != guessIn) { cout << ">> Unkown word" << endl ; return false ; } if (CheckPart(*guess, *answer, results)) { cout << ">> Correct" << endl ; return true ; } ShowMatch(results, *guess); } cout << ">> Failed" << endl ; return false ; }
还有就是这令人发指的运行速度,不会多核多线程优化所以没办法
学了OS后的补充:现在会了
但是可以加入计时函数量化我的痛苦 :)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <time.h> double CheckTime (clock_t &start, clock_t end) double delta = double (end - start) / CLOCKS_PER_SEC; start = end; return delta; } int main () clock_t clockStart; clockStart = clock(); cout << "time length: " << CheckTime(clockStart, clock()) << endl ; }
windows下g++编译,depth=0跑完16个大约是12s,depth=1跑完4个大约是32s,我大概是花了4~5h跑完所有数据
以及千万不要让测速度的脚本能覆盖结果,像我直接把之前算完的给覆盖了,全部重来
运行结果 经过排序发现
研经铸史
是handle的最优开头,且在depth=1的情况下E=14.8701,以ΔE=0.03的巨大差值(笑)和第二名拉开距离
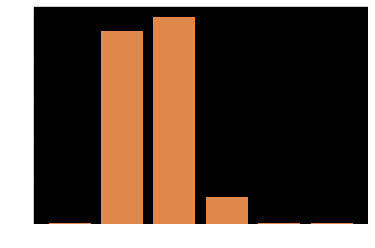
结果统计 基本全部正常的词在d0的E都在10以上,少数如“可口可乐”,d0E=6.55192,这样的词拉低了整体下限,整体d0E分布如下
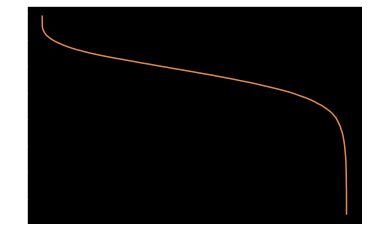
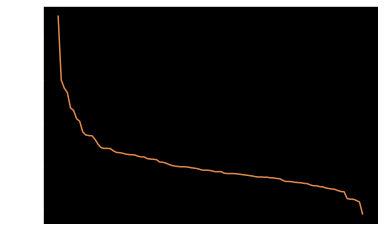
对于前d0E排名top100的词进行d1E的计算和排序,分布如下
日不动了,再见 UwU