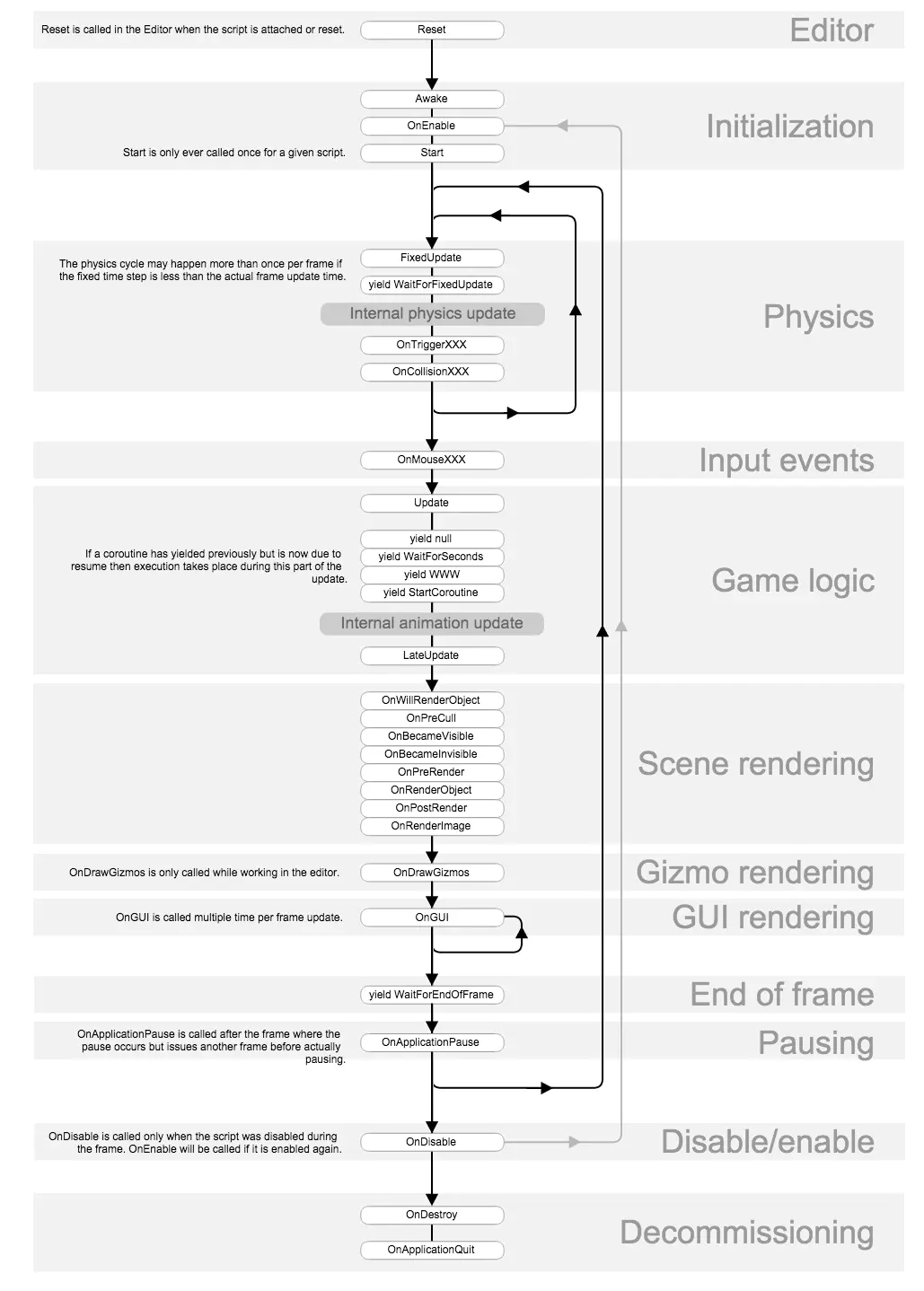
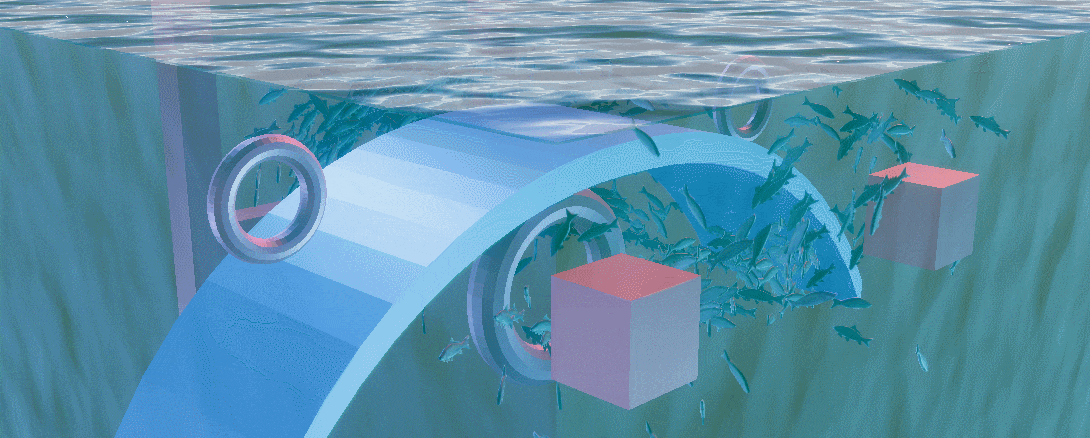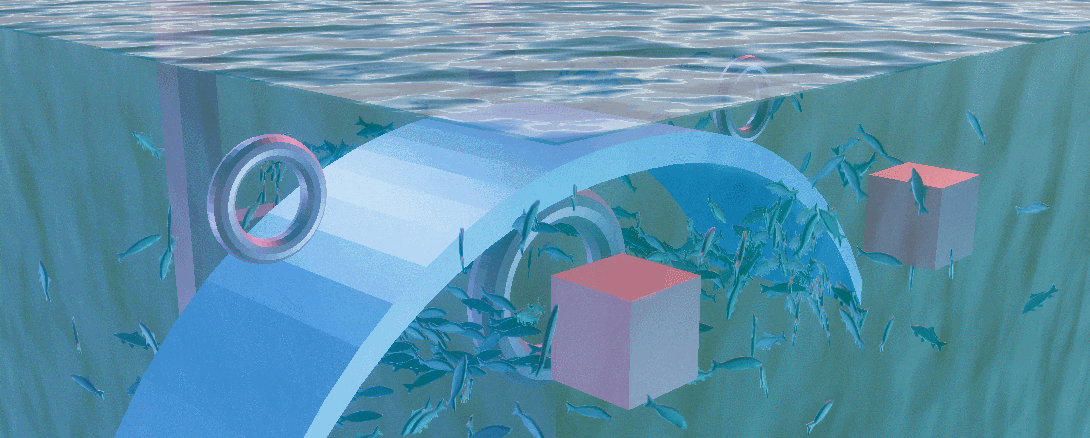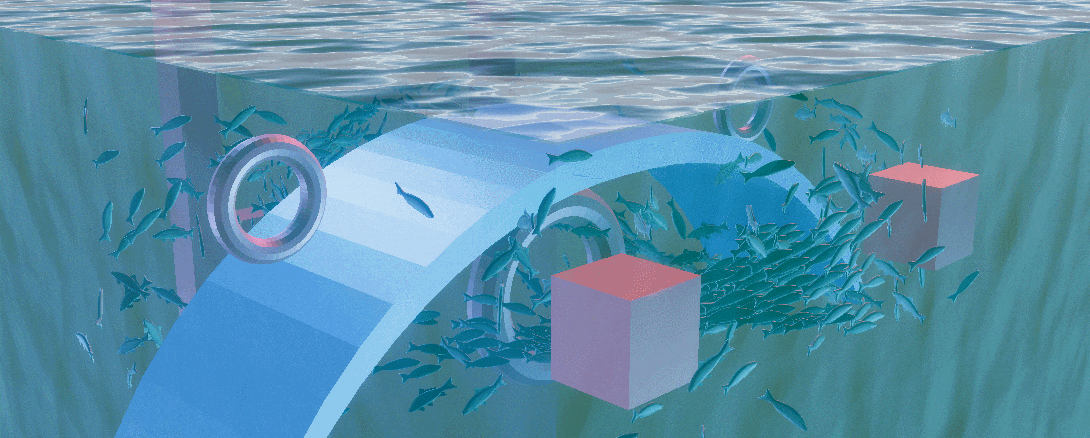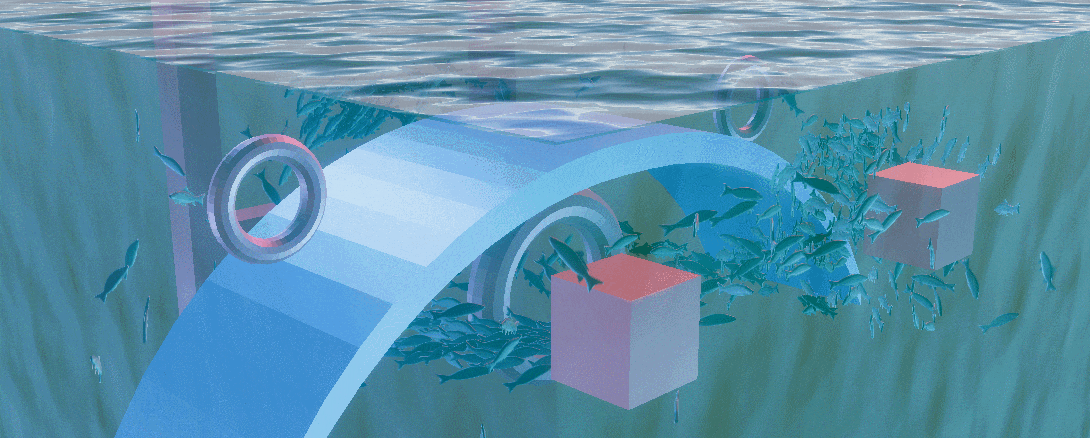Compute Shader and Boid
最近刷油管看到一个关于生物群模拟的Unity小项目,其中提到了使用ComputeShader来实现多线程的并行计算,感觉很适合入门,就做了一些尝试和改良

Compute Shader and Boid

- 首先,什么是
ComputeShader?
A Compute Shader is a Shader Stage that is used entirely for computing arbitrary information. While it can do rendering, it is generally used for tasks not directly related to drawing triangles and pixels.
简单地说,就是一个把任务从CPU移到GPU计算的shader就是ComputeShader。关于为什么要这么做,GPU是善于处理高度统一,重复性高的计算的,可以一次性把大量数据写入buffer,然后进行并发的计算,在实际表现中,使用了ComputeShader后的性能提升比纯C#脚本的效率提升了至少两倍
具体说说并发计算,其实也就是多线程,GPU进行多线程计算时,会等到当前buffer中的最后一项操作执行完成后再返回,这就导致类似短板效应的“长板效应”,我的粗略理解为执行一轮计算的时间是需要操作次数最多的一个线程,于是很明显,ComputeShader不能用于分支多,运行时间差异大的算法
- 其次,什么是
Boid?
对于生物群的模拟,根据 这篇文章,可以简单把生物群的行为抽象为以下三条
- Collision Avoidance: avoid collisions with nearby flockmates
- Velocity Matching: attempt to match velocity with nearby flockmates
- Flock Centering: attempt to stay close to nearby flockmates
也就是:避免碰撞,速度匹配,位置居中。还有不同的抽象方法,越细致的规则能塑造的群体必然也会越复杂,但其实只要应用了这三个规则,就已经很够看了
本工程将群落明确为鱼群,接下来将会从鱼群的抽象规则进行小规模模拟,到应用ComputeShader模拟大规模鱼群,最后使用ShaderGraph制作鱼的摆动以及水面来完善整个工程,为其润色
其实当真的敲代码的时候会发现约束鱼群的规则都非常简单,但是多个个体所组成的系统确实复杂的
Getting Start
因为我自己也是Unity入门,对于里面的Rigibody之类的内置力学系统不太了解,也不知道通常的处理这类力学问题的解决方案,恰好我手上拿到的油管dalao的示例代码用的是公式法,即将速度,加速度都保存在变量里,我就照搬他的做法了
为了后期的调参便利(调参真的是一个很麻烦的事情),我将根据三条规则所产生的加速度捆绑为一种类型的加速度,再将规避障碍物的加速度捆绑为另一种加速度,然后对每种类型的加速度分别进行更细致的权重分配
为了便于管理鱼群的行为,将 处理当前的鱼与其他剩余的鱼的代码 与 鱼自身Update的代码 分开编辑是很重要的,不管是编辑的便利还是运行的效率,每次查找其他鱼的时候都FindObjectsOfType<Boid>()一个新的列表是完全没有必要的,所以把这部分与其他鱼产生联系的代码抽象为一个BoidManager类,把更新自身速度等信息的代码放在Boid自己的类里面作为成员才是合理的
关键函数:
FindObjectsOfType<Boid>()按类查找Awake()与Start()注意Awake方法比Start先执行就行
Rules
Collision Avoidance
当前对象与每条鱼位置向量之差即为偏移量,用偏移量的单位向量除以偏移量的模以获得一个基于位置远近的加速度即可
avoidAcceleration -= posOffest.normalized / posOffset.magnitude
Velocity Matching
当前对象与每条鱼朝向向量之差即为偏移量,因为其实实际运行中速度的大小差异不会很大,速度方向却会有很大差异,所以只用匹配一下朝向即可
headingAcceleration += forwardOffest
Flock Centering
这其实就是第一条规则去掉距离远近的加权
Result
1 | for (int anoBoidIndex = 0; anoBoidIndex < boids.Length; anoBoidIndex++) { |
其中引入了几个Radius作为是否影响当对象的阈值以限制鱼的视力范围
应用了三个规则后可以如下GIF的效果

我在一个圆内在随机的位置以随机的朝向生成了一些鱼,不难发现他们很快就会根据自己的位置与朝向形成几个鱼群,但这些鱼群都十分稳定,这是因为虽然他们受群聚规则的限制,但没有一个外力来破坏这一规则限制出的稳定结构,我们想看到的必然不是一个稳定结构的鱼群
对于外力,我们可以选择增加一个驱逐者来追赶鱼群,类似于 这个视频,也可以增加障碍物来阻挡鱼群,在此为了场景的多样性,我选择后者
Obstacle Avoidance
其实上述的鱼群行动规则非常简单,不管是字面上看起来还是代码上敲起来,这也使得在空旷环境中的鱼群看起来很没意思,所以加入一个避障的function来使它更有趣吧
要使鱼避开前方的障碍物,首先想到的便是Physics.Raycast()射线检测,但此函数对CPU貌似不怎么友好,大量运行此函数卡成PPT,而单个的射线检测也是检测到物体时就返回了,均具有执行时间具有高度不确定性的特征,不适宜使用ComputeShader来提速,故唯一的解决方案就是尽可能地减少射线数量
在示例工程中,这位老哥使用了 这种方法 来使点阵在球面上近似均匀分布,然后对每个点做射线检测,大致是对黄金螺线做极径开个根号,使得螺线上的点均匀摊开,BEAUTIFUL
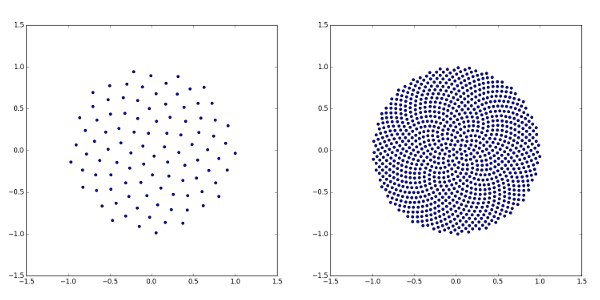
而从圆面到球面,把极径换成φ就过来了
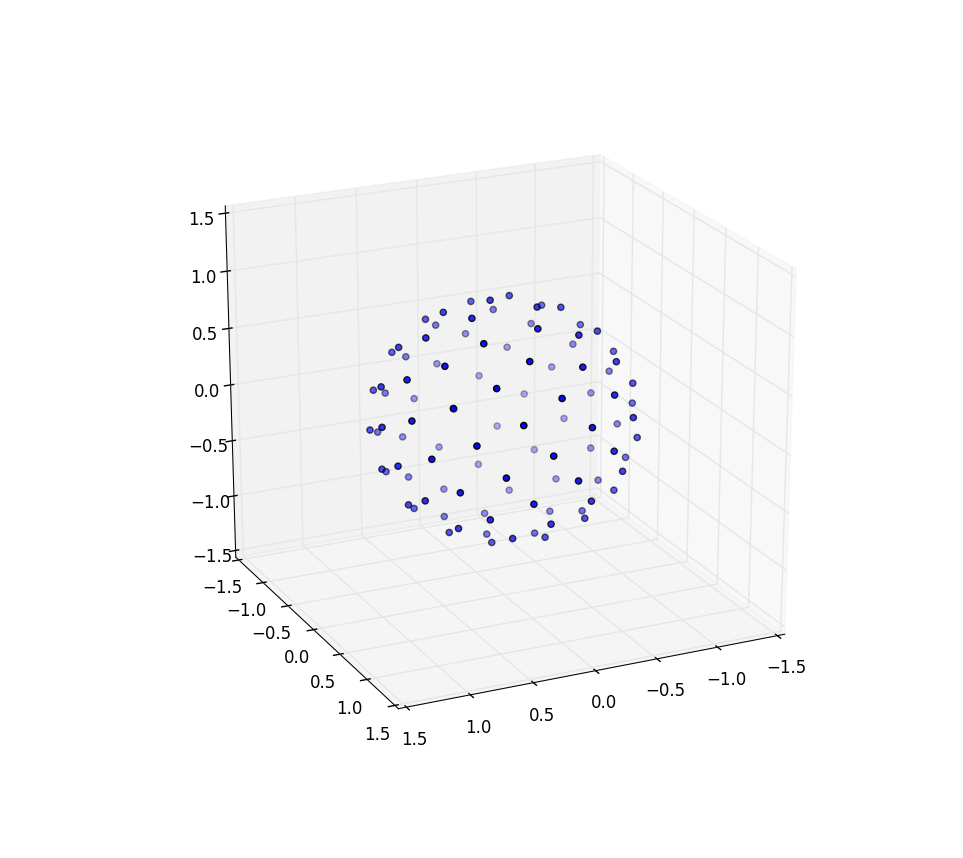
表达可能不太清楚,但只要动手调一下参,模拟一下螺线的变化就很明白了
1 | public const int numDivide = 15; |
示例工程中这位老哥应该也是怕射线太多导致卡顿,方案比较暴力,就是从前方开始检测,一旦检测到空旷处就直接加个距离的权重然后应用到加速度上并直接break掉循环了,也就是说鱼会朝着第一个检测到的空旷处游去。

这不免导致了一个问题,那就是鱼最后会和障碍物表面相切,然后贴着障碍物表面移动,先不说这样会导致在下一次受到扰动时穿模的问题,这种款式的鱼群简直像极了一群大耗子

所以既然在场景不会很复杂的时候使用这么多射线属实没有必要,经过实际测试,使用几条射线分辨侧面环境并且不break射线检测的循环,使鱼充分认知到周围环境,将此与上述等分检测的方法组合便是一个更优解,此处我选择的是12条射线,即xy平面上60°等分,再在φ=45°的圆周上也60°等分
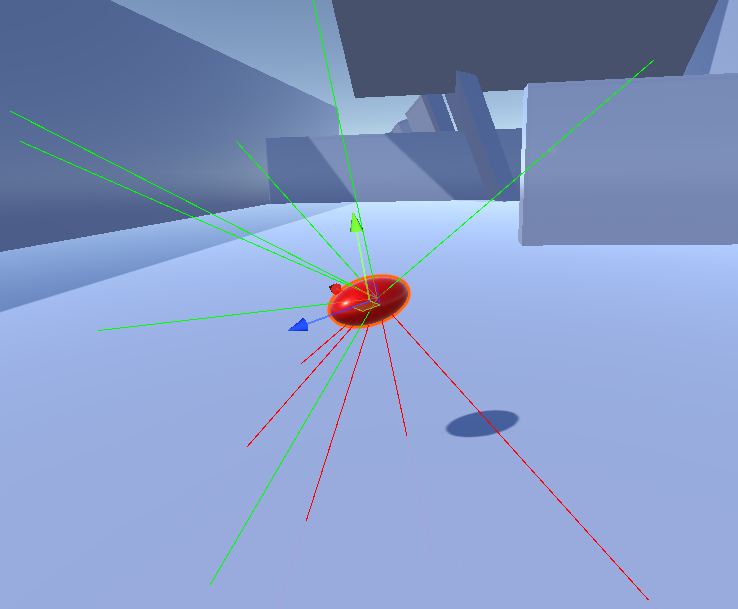
避障的相关代码因为不涉及其他鱼,选择把代码放在了Boid类下,但这会导致调参的时候需要在Unity中频繁切换Inspector,解决方案是把参数全部放到一个Setting类中,此类继承ScriptableObject,这样不仅解决了Inspector的问题,还使得Prefab在被拷贝时通过reference访问数据,避免了多次拷贝造成的内存浪费,也提升了在运行中调参时的整体性,运行中进行的调参也得以直接保存而不用Copy Component Values了
Front
在进行正面避障时,如果提供的射线少了则会使得鱼的速度方向变化过大,不够平滑,所以正面避障直接采用黄金螺旋法在球面上等距取点,从正面开始遍历这些点,一旦取到一个可转向的范围就break即可
1 | public Vector3 AvoidObstacleDir(){ |
Around
示例工程中因为缺少了对周围障碍物的检测,导致了大量因为贴近物体表面移动而穿过Collider的行为,所以在周围加入少量的Raycast,使得鱼也不会过于靠近四周的障碍
1 | public Vector3 KeepDstWithObstDir(){ |
Result
至此鱼群的模拟已经基本完成,接下来要做的便是将Rules部分的代码移植到ComputeShader中计算,以减轻CPU的负担

除了使用障碍物破坏鱼群的稳定结构,加入捕食者、食物之类的机制也可以为鱼群系统增添复杂性与趣味性,不妨自己尝试一下
Compute Shader
WTF is this
不妨使用文档中的示例来解释一下ComputeShader,下面这个ComputeShader将一个材质涂红
1 | #pragma kernel FillWithRed |
可见ComputeShader使用HLSL语言,也就是High Level Shader Language,因为通常只是拿来做数学计算,所以基本上只要装一个hlsl的代码提示的extension就可以直接开始写了
#pragma kernel FillWithRed:首先定义了一个核函数,函数名默认是CSMain,这是compute shader的函数入口,你也可以定义多个入口,因为本工程只需要一个入口,多个入口的ComputeShader暂时没有多做了解
[numthreads(1,1,1)]:规定了使用的线程组大小,这里使用的是单线程,默认是(8,8,1),线程数量为8x8x1,也就是64线程作为一个线程组。更多地了解numthreads 会发现里面东西挺多,涉及到显卡的硬件
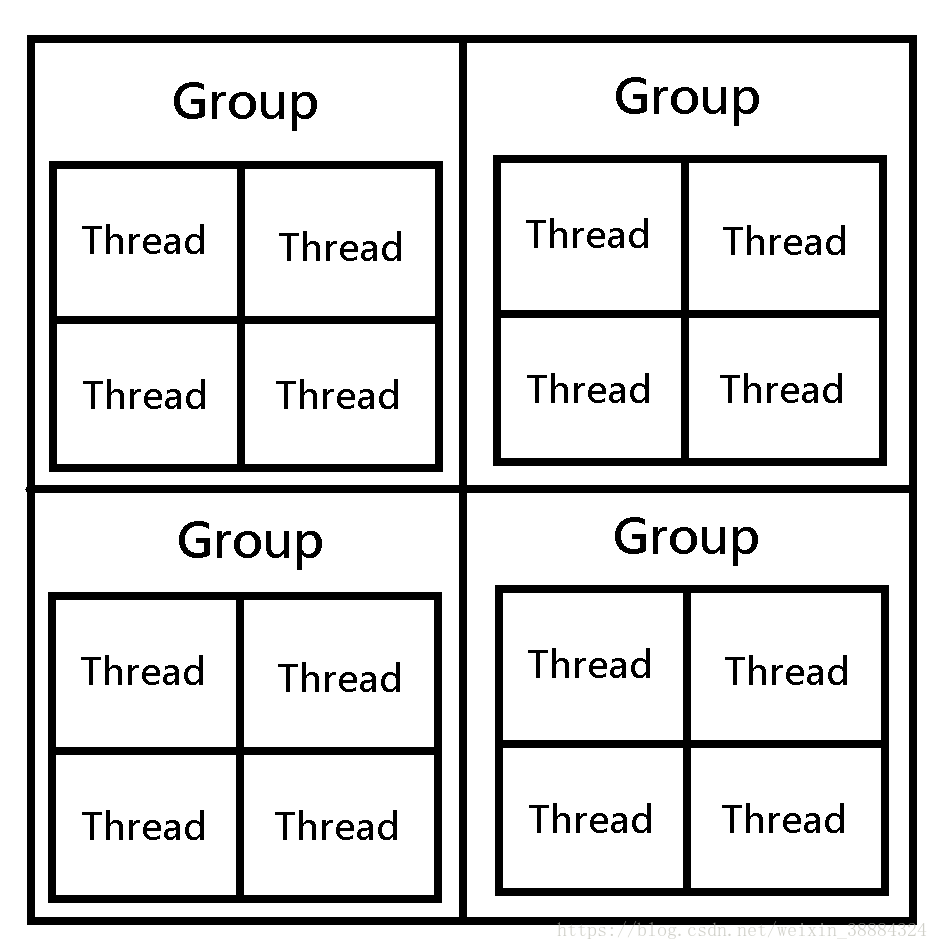
如上图,numthreads规定了一个Group(线程组)中的线程数量,Dispatch()作为C#脚本调用ComputeShader的交互方式,与numthread有一些联系,在介绍完Unity的官方ComputeShader示例后会提到。至于为什么大小由一个三维数组确定,是为了在访问2D或者3D的数据结构的时候更加方便操作(大概是吧)
The ability to specify the size of the thread group across three dimensions allows individual threads to be accessed in a manner that logically 2D and 3D data structures
在实际使用中,一般不会使numthreads小于32,这会达不到最低线程数导致多核围观;但也不能超过1024,应该也是硬件层面的限制。根据之前提到的CSDN上的建议:
AMD:ThreadSize 使用 64 的倍數 ( wavefront 架構 ) NVIDIA:ThreadSize 使用 32 的倍數 ( SIMD32 (Warp) 架構 )
这么一看官方初始线程数选择64还挺合理的,但我们仍然需要根据自己的实际需求以及预期的线程组数来选择具体的numthread
ID:在声明方法时提到了ID的概念,即void FillWithRed (uint3 dtid : SV_DispatchThreadID)中的SV_DispatchThreadID,其实这些三维的ID基本上就是index了
SV_GroupID : 線程組 ID SV_GroupThreadID : 線程組內的線程 ID (三維,你可以理解為 Group 內的座標) SV_GroupIndex : 線程組內的線程 ID (一維) SV_DispatchThreadID : 唯一ID (你可以理解成整張圖片座標)
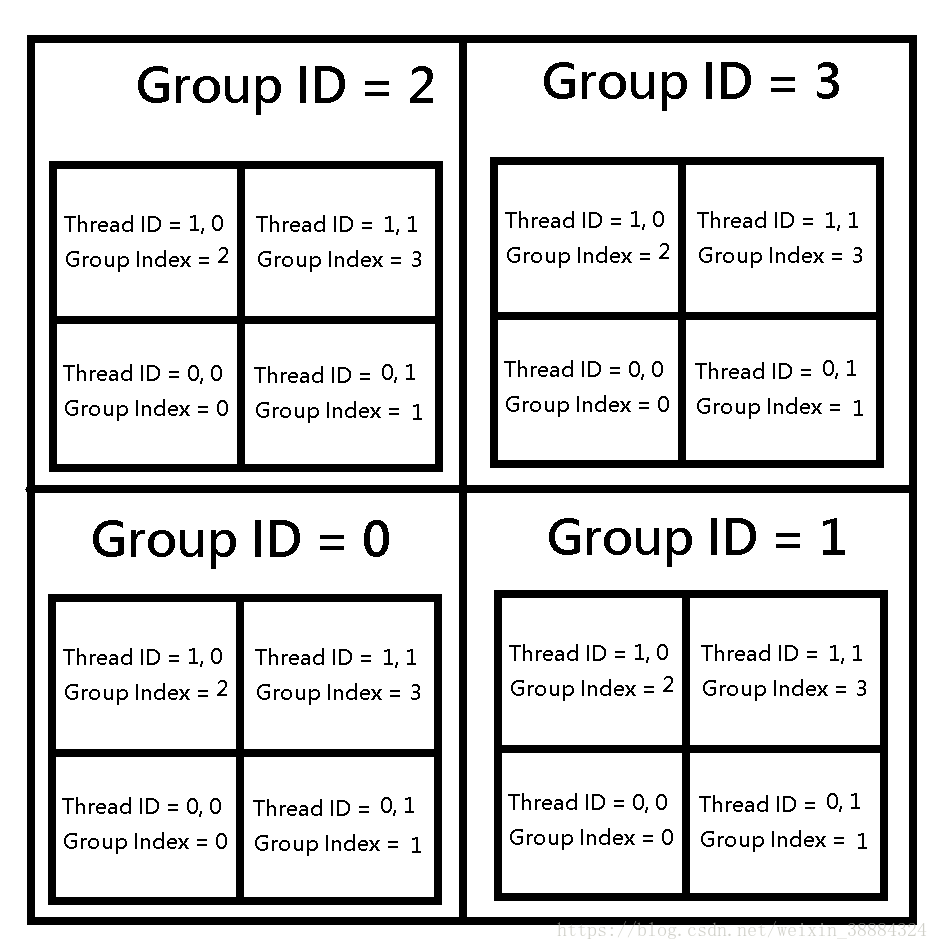
Dispatch(kernelIndex,x,y,z):用于在C#脚本中调用ComputeShader,第一个参数为核函数的index,如果是CSMain就直接是0,如果不确定index到底是多少,可以通过FindeKernel(String kernelName)获取index。关于后面的xyz,需要满足Dispatch*numthread>=numData,否则既然你的输入都不全,怎么获得一个完整的输出呢?
举几个栗子:
Eg1.输出ComputeShader的默认代码
ComputeShader在Unity中创建时初始化代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14// Each #kernel tells which function to compile; you can have many kernels
#pragma kernel CSMain
// Create a RenderTexture with enableRandomWrite flag and set it
// with cs.SetTexture
RWTexture2D<float4> Result;
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
// TODO: insert actual code here!
Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);
}可以使用一个C#脚本调用它
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18using UnityEngine;
public class Tester : MonoBehaviour
{
public ComputeShader cs;
public RenderTexture tex;
void Start() {
// 创建一个材质查看结果
tex = new RenderTexture(256,256,24);
// 一定要记得打开写入权限
tex.enableRandomWrite = true;
tex.Create();
// 在Dispatch前需要先传入参数
cs.SetTexture(0, "Result", tex);
// 注意到numthread为(8,8,1),有numthread*Dispatch=Resolution
cs.Dispatch(0, 256/8, 256/8, 1);
}
}得到一个好康的分形图案

Eg2.将参数改小
Dispatch(0,64/8,128/8,1);numthread[8,8,1];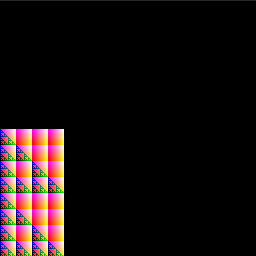
观察到图像不全且只有64x128,与Dispatch中传入的量吻合
Eg3.将参数改大
tex = new RenderTexture(256,300,24);Dispatch(0,256/8,(int)Mathf.Ceil(300/8),1);numthread[8,8,1];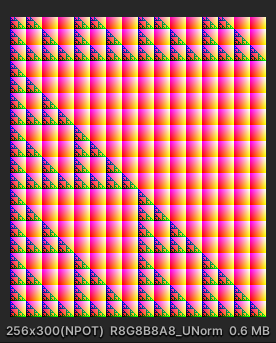
注意到
(int)Mathf.Ceil(300/8) * 8 > 300,如果此处不用Ceil向上取整则会少一部份没有被计算
Translation
C#翻译到hlsl的工作流程如下
首先是C#脚本上
创建结构体保存一些属性,其中
acceleration作为计算结果,等待在ComputeShader中被赋值1
2
3
4
5
6
7
8
9
10public struct BoidData {
public Vector3 position;
public Vector3 forward;
public Vector3 acceleration;
public static int Size {
get {
return sizeof (float) * 3 * 3;
}
}
}实例化,赋值,创建Buffer
1
2
3
4
5
6
7var boidData = new BoidData[boids.Length];
for (int i = 0; i < boids.Length; i++) {
boidData[i].position = boids[i].transform.position;
boidData[i].forward = boids[i].transform.forward;
}
var boidBuffer = new ComputeBuffer (boids.Length, BoidData.Size);
boidBuffer.SetData (boidData);传入ComputeShader计算需要的变量信息
1
2
3
4
5
6
7computeShader.SetBuffer(0, "boids", boidBuffer);
computeShader.SetInt("numBoids", boids.Length);
computeShader.SetFloat("viewRadius", viewRadius);
computeShader.SetFloat("avoidRadius", avoidRadius);
computeShader.SetFloat("avoidWeight", avoidWeight);
computeShader.SetFloat("headingWeight", headingWeight);
computeShader.SetFloat("centerWeight", centerWeight);通过
Dispatch()开始执行ComputeShadercomputeShader.Dispatch(0, threadGroups, 1, 1);
现在把视角切换到ComputeShader上
把需要传入的变量都定义一遍,这里注意结构体使用了
RWStructuredBuffer作为容器A structured buffer is a buffer that contains elements of equal sizes. Use a structure with one or more member types to define an element. Here is a structure with three members.
1
2
3
4
5
6
7
8
9
10
11
12
13struct Boid {
float3 position;
float3 forward;
float3 acceleration;
};
RWStructuredBuffer<Boid> boids;
int numBoids;
float viewRadius;
float avoidRadius;
float avoidWeight;
float headingWeight;
float centerWeight;翻译一遍C#代码,只需要改一点语法就可以了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28void CSMain (uint3 id : SV_DispatchThreadID)
{
float3 zero3 = {0, 0, 0};
float3 avoidAcceleration = zero3;
float3 headingAcceleration = zero3;
float3 centerAcceleration = zero3;
int mateCount;
int avoidCount;
for(int i = 0; i < numBoids; i ++){
if((int)id.x != i){
float3 offset = boids[id.x].position - boids[i].position;
float sqrDst = offset.x * offset.x + offset.y * offset.y + offset.z * offset.z;
if(sqrDst < viewRadius * viewRadius){
mateCount += 1;
headingAcceleration += boids[i].forward - boids[id.x].forward;
centerAcceleration -= offset;
}
if(sqrDst < avoidRadius * avoidRadius){
avoidCount++;
avoidAcceleration += normalize(offset) / sqrDst;
}
}
}
avoidAcceleration = avoidCount == 0 ? zero3 : normalize(avoidAcceleration);
headingAcceleration = mateCount == 0 ? zero3 : normalize(headingAcceleration);
centerAcceleration = mateCount == 0 ? zero3 : normalize(centerAcceleration);
boids[id.x].acceleration = avoidAcceleration * avoidWeight + headingAcceleration * headingWeight + centerAcceleration * centerWeight;
}
关于numthread,示例工程直接设了[1024,1,1]:使用一维向量是因为需要处理的数据没有类似材质、体积之类的三维结构体;1024是为了直接把线程拉满
Result
将原本在CPU中进行的大量重复计算迁移至GPU后可模拟的鱼群规模瞬间提升了不少,现在你可以模拟一些较大规模的鱼群了,在此就不附新的图片了
Polish
就算为其换上一个真正的鱼🐟的模型,现在的鱼群整体还比较单调,虽然有了一些规则使得其在宏观动态的表现力上有了那么一捏捏,但还缺少一些更加直观的细节,说白了就是有一个有趣的灵魂但没有华丽的外表,所以我们不妨做两个shader来为其润色,一个shader负责鱼的摆动,另一个负责水面材质
我使用的是HDRP作为渲染管线,虽然我不会用它,但我听说他很强,所以我希望能迈出第一步
由于目前使用的是ShaderGraph,不便于附代码,只能讲一下思路并附带一些资料了
Waving Fish
其实可以用一个sin(t)函数就能获得很能接受的效果了,但是鉴于鱼都是成群出现,以时间为变量的函数肯定是不行的,我当前的做法是将鱼的世界坐标作为变量,输入到Gradient Noise,对鱼的顶点坐标的某一个轴向应用这个噪声,这样得到的鱼会根据自身位置而决定摇摆,缺点是没有和鱼的转向、运动等联系起来,在设想中,能根自身加速度选择摇摆方式的Shader才是最好的,但目前不清楚这样做的可行性以及具体方法
接下来还需要将鱼头的摇摆幅度降低,因为一般来说鱼头不会像尾巴和身体那样剧烈摆动。在此推荐了解一下有关UV的概念,这很重要,比如此处可以将UV的x作为变量,在噪声和原本的顶点位置之间做线性插值(LERP),也可以对UV.x取平方之类的以让摆动的过度更加自然
综上,便得到了一条欢快的小鱼🐟

Water Surface Shader
鱼得到了升级,还需要一个容器来使得整个场景在水中,这里选择制作一个水面的材质贴在平面上,做成开头那样的水立方,Unity官方提供了 基本的水面ShdaerGraph教程,由于处处碰壁,我也就基本是抄了一遍官方的成果
主要的思想是使Scene Depth与Screen Position相减,由于前者的检测不包含透明物体,而后者包含,则可以获取穿过一个透明平面后的空间深度信息

之后只需要在这个平面的表面做两层不同细节程度的水面Normal Map的反向滚动,再加入由噪声控制的平面顶点坐标的起伏即可
Final Result
Check the final result if you want, a gif about 10 Mb